This is part 3 of my storage update; see
Part 1, on DNA storage, and
Part 2, on SSD reliability. This is Part 3, on the 2022 Library of Congress "Designing Storage Architectures" meeting. The agenda with links to the presentations is
here. Below the fold I have comments on some of them.
Henry has been a fixture at these meetings since 2001 and this was to be his last. He started out explaining why "it takes longer than it takes" using the example of Jim Gray's 2006 presentation
Tape is Dead, Disk is Tape, Flash is Disk, RAM Locality is King — the whole presentation is in his backup slides and is well worth reading.
He uses Q2 2021 data from Trendfocus to show that, in the enterprise space, HDD shipments were 247.61EB versus SDD shipments of 35.79EB. For SSDs to displace HDDs in the enterprise would require increasing production by a factor of nearly 7. There is no way to justify the enormous investment in flash fabs that would require.
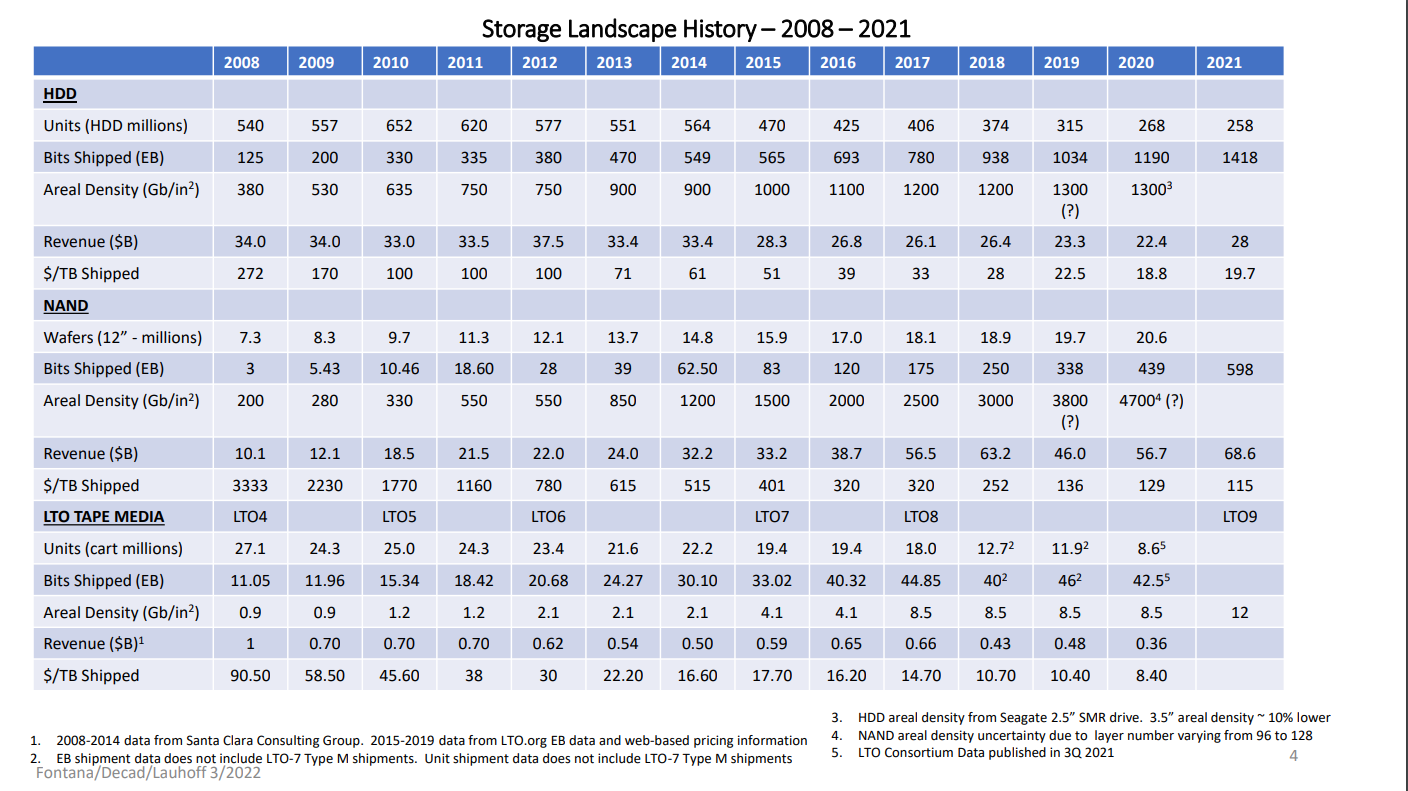
He presented the continuation of the invaluable work at IBM by Robert Fontana and Gary Decad. Their latest "Storage Landscape" shows the continuing decrease in HDD units shipped, down from a peak in 2010 of 652M to 2021s 258M, but a continuing increase in bits shipped from 2010's 330EB to 2021's 1418EB. Over the same period wafers of NAND have more than doubled from 9.7M to 20.6M and bits increade around 60-fold to 598EB. The big difference in the technologies is still in revenue per TB, with HDD at $28 versus NAND at $115.
Their graph of areal density clearly shows the difficulty HDD vendors are having as, even with HAMR and MAMR, they close in on the physical limits of magnetic storage. The closer they get, the more expensive getting each increment from the lab to the market becomes. Tape, with more than two roders af magnitude lower areal density, has a much easier time and is increasing areal density around the rates that HDDs did until 2010. NAND has been increasing areal density very rapidly, but most of that is from increasing layers from 2D (1) to 3D (128) and going from 1 bit/cell to 4 bit/cell. They can't go to 4D, and the feature size on the wafers isn't increasing that fast. Projecting that the recent increase will continue seems optimistic.
Their graph of the cost ratio between Flash and Tape against HDD throws some cold water on the idea that disk will go the way of the Dodo any time soon. Flash is gradually eroding HDD's cost advantage, but it still has a factor of 6 to go, which will take many years. Eyeballing the line on the graph suggests price parity in around a decade but, as I discuss in the previous paragraph, the current rate of increase in flash density is unlikely to be sustainable.
I've been skeptical of Seagate's roadmaps since Dave Anderson's
presentation to the 2009 edition of this meeting, and this bias wasn't helped by Trantham using the numbers IDC
pulls out of thin air for his "gee-whiz" 5th slide about the amount of data in 2025.
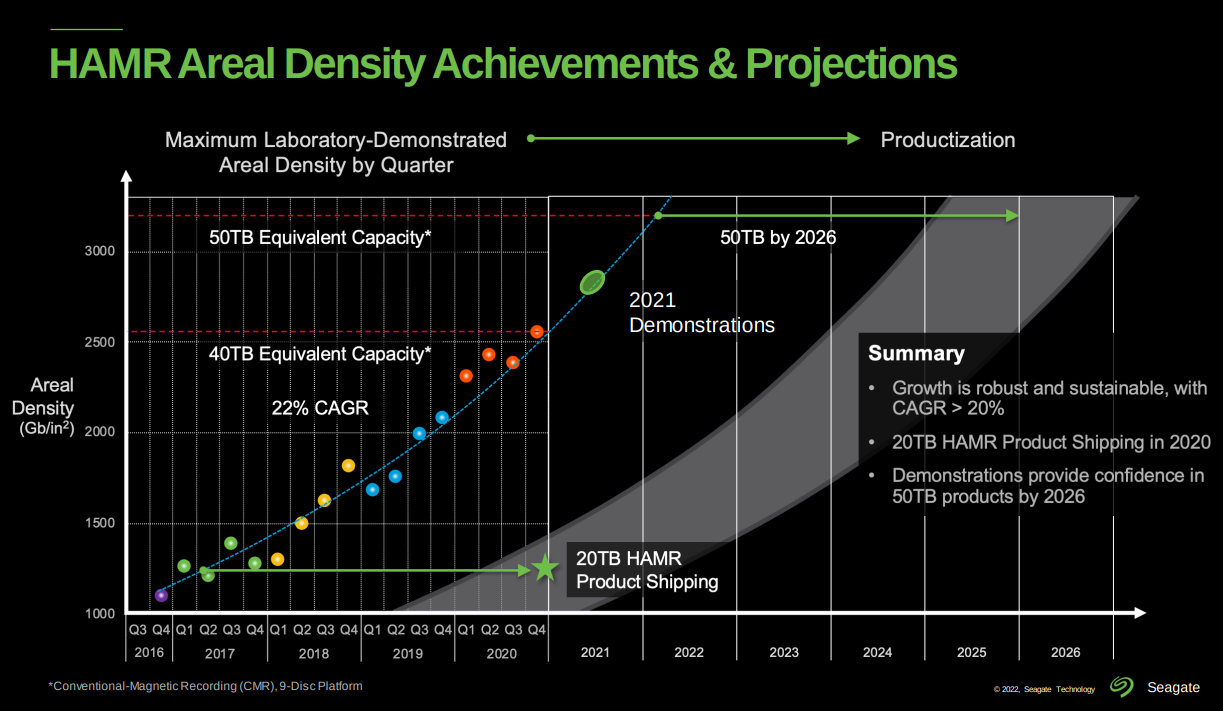
He provided another of Seagate's roadmaps, showing that it took 4 years to get HAMR into limited production from a lab demo of the specific technology, and projecting a 20% CAGR leading to drives with "50TB by 2025". Now they're over the hump of getting the first HAMR drive into production, future technology evolution should be easier. But based on the decade-plus track record of their roadmaps, I'd apply a grain of salt.
He did make some interesting points:
- Data continues to shift to the cloud; however, we are now seeing more data kept at the edge
- Content distribution and the cost & latency of networking are key drivers
- Most of cloud data is stored on large-capacity nearline hard disk drives
And:
Seagate Announced the first NVMe HDD at OCP last November
...
CDUs will be available in Mid-2024 in Single and Dual-Port SKUs
Moving all storage to the NVMe interface is an interesting trend.
To do Seagate justice, their slides have much more meat to them than Paul Peck's
HDD Storage in the Zettabyte Era from Western Digital, which is almost content-free.
Delgadillo discussed my long-time
bête noir, namely how a digital preservation system using cloud storage can confirm the fixity of content, i.e. that the content is unchanged from when it was submitted.
He showed the use of the Google Cloud command
gsutil stat, which returns the CRC32 and MD5 checksums. The relevant documentation is
stat - Display object status:
the gsutil stat command provides a strongly consistent way to check for the existence (and read the metadata) of an object.
CRC32C and Installing crcmod says:
gsutil automatically performs integrity checks on all uploads and downloads. Additionally, you can use the gsutil hash command to calculate a CRC for any local file.
hash - Calculate file hashes says:
Calculate hashes on local files, which can be used to compare with gsutil ls -L output. If a specific hash option is not provided, this command calculates all gsutil-supported hashes for the files.
Note that gsutil automatically performs hash validation when uploading or downloading files, so this command is only needed if you want to write a script that separately checks the hash.
Note this command hashes the local files, not the files in the could. Uploading and downloading is performed by the
cp command.
cp - Copy files and objects says:
At the end of every upload or download, the gsutil cp command validates that the checksum it computes for the source file matches the checksum that the service computes. If the checksums do not match, gsutil deletes the corrupted object and prints a warning message.
...
If you know the MD5 of a file before uploading, you can specify it in the Content-MD5 header, which enables the cloud storage service to reject the upload if the MD5 doesn't match the value computed by the service.
The problem is that the application has no way of knowing
when or even
whether the hashes in the metadata were computed. The Content-MD5 header tells the storage service what the MD5 is; it could discard the content and respond correctly to the
gsutil stat command by remembering only the MD5. The preservation application would discover this only when it tried to download the content. Or some background process in the cloud could have computed the MD5 and validated the content against the roginal MD5 some time ago, which doesn't validate the content
now.
Ideally, the storage service API would have a command that supplied an application generated random nonce to be prepended to the content, forcing the service to hash it at the time of the command. Anything less requires the application to either (a) trust the storage service, which is not appropriate for preservation audits, or (b) regularly download the entire stored content to hash it locally, which cost too much in bandwidth charges to be practical. Absent a nonce, the API should at least provide a timestamp at which it claims to have computed the hashes.
Storage Services
There followed presentations from a range of other preservation storage services, which were mostly vanilla marketing:
The only real news was an enhancement to Amazon S3's API, more fully described by Jeff Barr in
New – Additional Checksum Algorithms for Amazon S3, that you could now use SHA-1, SHA-256, CRC-32, and CRC-32C as well as MD5 as checksums and that GetObjectAttributes had been added to the API to get all the available attributes in one call. Note that this API, like
gsutil, returns the checksums with no nonce or evidence of when they were validated.
DNA
The last session I want to discuss featured five presentations on storing data in molecules:
- Microsoft/UW. Karin Strauss pointed to their recent publications, some of which I've already covered.
- Catalog. In Part 1 I wrote:
Three years ago I reported on Catalog, who encode data not in individual bases, but in short strands of pre-synthesized DNA. The idea is to sacrifice ultimate density for write speed. David Turek reported that, by using conventional ink-jet heads to print successive strands on dots on a polymer tape, they have demonstrated writing at 1Mb/s.
- Datacule, which encodes data in flourescent dyes. The combination of dyes encodes multiple bits (8) in a printed dot (press). The abstract of Storing and Reading Information in Mixtures of Fluorescent Molecules by Amit A. Nagarkar et al reads:
This work shows that digital data can be stored in mixtures of fluorescent dye molecules, which are deposited on a surface by inkjet printing, where an amide bond tethers the dye molecules to the surface. A microscope equipped with a multichannel fluorescence detector distinguishes individual dyes in the mixture. The presence or absence of these molecules in the mixture encodes binary information (i.e., “0” or “1”). The use of mixtures of molecules, instead of sequence-defined macromolecules, minimizes the time and difficulty of synthesis and eliminates the requirement of sequencing. We have written, stored, and read a total of approximately 400 kilobits (both text and images) with greater than 99% recovery of information, written at an average rate of 128 bits/s (16 bytes/s) and read at a rate of 469 bits/s (58.6 bytes/s).
The presentation claims 5Mbit/in2 areal density.
-
Twist Bioscience, who showed a very realistic "reality check" on their progress. They are working towards a goal of a 2D array on a chip that synthesizes 1TB of DNA at a time, which is then washed into a vial for storage — they are working on a 62.5GB chip. The vials are packed into the standard biochem trays, for 1,536TB for the largest tray.





1 comment:
I was actually in charge of the validation/auditing of objects in Seagate-EVaults abortive attempt at an archiving focused cloud storage service.
We had a couple libraries working with us on the early versions, and we actually looked at a "nonce" based approach, but we ended up nuking it not because it was difficult, but because the library folks were basically saying "Well, we can do this as a way to trust that you got what we uploaded, but it doesn't seem to be much different than just going with a generic hash/checksum we each do anyway."
We also never came up with a satisfactory answer for that no really, we have 3 independent copies beyond "Trust us", given we were working with OpenStack swift as our base system + some mods for more aggressive integrity checking and tracking. The nonce conversation came up again for this, but we wound up in the a similar position of "There's nothing stopping us from just storing said checksums and lying to you about how many copies we actually stored" so we all agreed it probably wasn't worth the effort for the moment.
Bit of a tangent, but I still think parts of the failure (among many in basic project management) 1) was that there was too much of a focus on data integrity, and not enough on making the archived data inherently useful for something beyond just extra copies which there were easier/cheaper methods of doing. 2) there were interfaces on the "other side" that produced pathological workloads for the cloud store at the time (i.e. a block-to-object gateway that firehosed a bajillion tiny objects at the back end)
Post a Comment