Everyone interested in academic communication should read Amy Fry's magisterial Conventional Wisdom or Faulty Logic? The Recent Literature on Monograph Use and E-book Acquisition. She shows how, by endlessly repeating the conclusion of a single study of a single library now more than 35 years out of date, publishers and their consultants have convinced librarians that traditional collection development has failed and needs to be replaced by patron-driven acquisition. And how, building on this propaganda victory, they moved on to convince librarians that, despite studies showing the opposite, readers across all disciplines preferred e-books to print. Below the fold, some details.
Wednesday, December 30, 2015
Monday, December 28, 2015
Annotation progress from Hypothes.is
I've blogged before on the importance of annotation for scholarly communication and the hypothes.is effort to implement it. At the beginning of December Hypothesis made a major announcement:
On Tuesday, we announced a major new initiative to bring this vision to reality, supported by a coalition of over 40 of the world’s essential scholarly organizations, such as JSTOR, PLOS, arXiv, HathiTrust, Wiley and HighWire Press, who are linking arms to establish a new paradigm of open collaborative annotation across the world’s knowledge.Below the fold, more details on this encouraging development.
Wednesday, December 23, 2015
Signposting the Scholarly Web
At the Fall CNI meeting, Herbert Van de Sompel and Michael Nelson discussed an important paper they had just published in D-Lib, Reminiscing About 15 Years of Interoperability Efforts. The abstract is:
Over the past fifteen years, our perspective on tackling information interoperability problems for web-based scholarship has evolved significantly. In this opinion piece, we look back at three efforts that we have been involved in that aptly illustrate this evolution: OAI-PMH, OAI-ORE, and Memento. Understanding that no interoperability specification is neutral, we attempt to characterize the perspectives and technical toolkits that provided the basis for these endeavors. With that regard, we consider repository-centric and web-centric interoperability perspectives, and the use of a Linked Data or a REST/HATEAOS technology stack, respectively. We also lament the lack of interoperability across nodes that play a role in web-based scholarship, but end on a constructive note with some ideas regarding a possible path forward.They describe their evolution from OAI-PMH, a custom protocol that used the Web simply as a transport for remote procedue calls, to Memento, which uses only the native capabilities of the Web. They end with a profoundly important proposal they call Signposting the Scholarly Web which, if deployed, would be a really big deal in many areas. Some further details are on GitHub, including this somewhat cryptic use case:
Use case like LOCKSS is the need to answer the question: What are all the components of this work that should be preserved? Follow all rel="describedby" and rel="item" links (potentially multiple levels perhaps through describedby and item).Below the fold I explain what this means, and why it would be a really big deal for preservation.
Monday, December 21, 2015
DRM in the IoT
This week, Phillips pushed out a firmware upgrade to their "smart" lighting system that prevented third-party lights that used to interoperate with it continuing to do so. An insightful Anonymous Coward at Techdirt wrote:
And yet people still wonder why many people are hesitant to allow any sort of software update to install. Philips isn't just turning their product into a wall garden. They're teaching more people that "software update"="things stop working like they did".Below the fold, some commentary.
Tuesday, December 15, 2015
Talk on Emulation at CNI
When Cliff Lynch found out that I was writing a report for the Mellon Foundation, the Sloan Foundation and IMLS entitled Emulation & Virtualization as Preservation Strategies he asked me to give a talk about it at the Fall CNI meeting, and to debug the talk beforehand by giving it at UC Berkeley iSchool's "Information Access Seminars". The abstract was:
20 years ago, Jeff Rothenberg's seminal Ensuring the Longevity of Digital Documents compared migration and emulation as strategies for digital preservation, strongly favoring emulation. Emulation was already a long-established technology; as Rothenberg wrote Apple was using it as the basis for their transition from the Motorola 68K to the PowerPC. Despite this, the strategy of almost all digital preservation systems since has been migration. Why was this?Below the fold, the text of the talk with links to the sources. The demos in the talk were crippled by the saturated hotel network; please click on the linked images below for Smarty, oldweb.today and VisiCalc to experience them for yourself. The Olive demo of TurboTax is not publicly available, but it is greatly to Olive's credit that it worked well even on a heavily-loaded network.
Preservation systems using emulation have recently been deployed for public use by the Internet Archive and the Rhizome Project, and for restricted use by the Olive Archive at Carnegie-Mellon and others. What are the advantages and limitations of current emulation technology, and what are the barriers to more general adoption?
Thursday, December 10, 2015
SSDs: Cheap as Chips?
Four and a half years ago Ian Adams, Ethan Miller and I proposed DAWN, a Durable Array of Wimpy Nodes, pointing out that a suitable system design could exploit the characteristics of solid-state storage to make system costs for archival storage competitive with hard disk despite greater media costs. Since then, the cost differential between flash and hard disks has decreased substantially. Below the fold, an update.
Tuesday, December 8, 2015
National Hosting with LOCKSS Technology
For some years now the LOCKSS team has been working with countries to implement National Hosting of electronic resources, including subscription e-journals and e-books. JISC's SafeNet project in the UK is an example. Below the fold I look at the why, what and how of these systems.
Thursday, November 19, 2015
You get what you get and you don't get upset
The title is a quote from Coach Junior, who teaches my elder grand-daughter soccer. It comes in handy when, for example, the random team selection results in a young lady being on the opposite team to her best friend. It came to mind when I read Kalev Leetaru's How Much Of The Internet Does The Wayback Machine Really Archive? documenting the idiosyncratic and evolving samples the Internet Archive collects of the Web, and the subsequent discussion on the IIPC mail alias. Below the fold, my take on this discussion.
Thursday, November 12, 2015
SPARC Author Addendum
SPARC has a post Author Rights: Using the SPARC Author Addendum to secure your rights as the author of a journal article announcing the result of an initiative to fix one of the fundamental problems of academic publishing, namely that in most cases authors carelessly give up essential rights by signing unchanged a copyright transfer agreement written by the publisher's lawyers.
The publisher will argue that this one-sided agreement, often transferring all possible rights to the publisher, is absolutely necessary in order that the article be published. Despite their better-than-average copyright policy, ACM's claims in this regard are typical. I dissected them here.
The SPARC addendum was written by a lawyer, Michael W. Carroll of Villanova University School of Law, and is intended to be attached to, and thereby modify, the publisher's agreement. It performs a number of functions:
Of course, many publishers will refuse to publish, and many authors at that point will cave in. The SPARC site has useful advice for this case. The more interesting case is the third, where the publisher simply ignores the author's rights as embodied in the addendum. Publishers are not above ignoring the rights of authors, as shown by the history of my article Keeping Bits Safe: How Hard Can It Be?, published both in ACM Queue (correctly with a note that I retained copyright) and in CACM (incorrectly claiming ACM copyright). I posted analysis of ACM's bogus justification of their copyright policy based on this experience. There is more here.
So what will happen if the publisher ignores the author's addendum? They will publish the paper. The author will not get a camera-ready copy without DRM. But the author will make the paper available, and the "kicker" above means they will be on safe legal ground. Not merely did the publisher constructively agree to the terms of the addendum, but they failed to deliver on their side of the deal. So any attempt to haul the author into court, or send takedown notices, would be very risky for the publisher.
Publishers don't need anything except permission to publish. Publishers want the rights beyond this to extract the rents that generate their extraordinary profit margins. Please use the SPARC addendum when you get the chance.
The publisher will argue that this one-sided agreement, often transferring all possible rights to the publisher, is absolutely necessary in order that the article be published. Despite their better-than-average copyright policy, ACM's claims in this regard are typical. I dissected them here.
The SPARC addendum was written by a lawyer, Michael W. Carroll of Villanova University School of Law, and is intended to be attached to, and thereby modify, the publisher's agreement. It performs a number of functions:
- Preserving the author's rights to reproduce, distribute perform, and display the work for non-commercial purposes.
- Acknowledges that the work may already be the subject of non-exclusive copyright grants to the author's institution or a funding agency.
- Imposes as a condition of publication that the publisher provide the author with a PDF of the camera-ready version without DRM.
Of course, many publishers will refuse to publish, and many authors at that point will cave in. The SPARC site has useful advice for this case. The more interesting case is the third, where the publisher simply ignores the author's rights as embodied in the addendum. Publishers are not above ignoring the rights of authors, as shown by the history of my article Keeping Bits Safe: How Hard Can It Be?, published both in ACM Queue (correctly with a note that I retained copyright) and in CACM (incorrectly claiming ACM copyright). I posted analysis of ACM's bogus justification of their copyright policy based on this experience. There is more here.
So what will happen if the publisher ignores the author's addendum? They will publish the paper. The author will not get a camera-ready copy without DRM. But the author will make the paper available, and the "kicker" above means they will be on safe legal ground. Not merely did the publisher constructively agree to the terms of the addendum, but they failed to deliver on their side of the deal. So any attempt to haul the author into court, or send takedown notices, would be very risky for the publisher.
 |
| 2012 data from Alex Holcombe |
Tuesday, November 10, 2015
Follow-up to the Emulation Report
Enough has happened while my report on emulation was in the review process that,
although I announced its release last week,
I already have enough material for a follow-up post. Below the fold, the details,
including a really important paper from the recent SOSP workshop.
Thursday, November 5, 2015
Cloud computing; Threat or Menace?
Back in May The Economist hosted a debate on cloud computing:
Big companies have embraced the cloud more slowly than expected. Some are holding back because of the cost. Others are wary of entrusting sensitive data to another firm’s servers. Should companies be doing most of their computing in the cloud?It was sponsored by Microsoft, who larded it with typical cloud marketing happy-talk such as:
The Microsoft Cloud creates technology that becomes essential but invisible, to help you build something amazing. Microsoft Azure empowers organizations with the creation of innovative apps. Dynamics CRM helps companies market smarter and more effectively, while Office 365 enables employees to work from virtually anywhere on any device. So whether you need on-demand scalability, real-time data insights, or technology to connect your people, the Microsoft Cloud is designed to empower your business, allowing you to do more and achieve more.Below the fold, some discussion of actual content.
Tuesday, November 3, 2015
Emulation & Virtualization as Preservation Strategies
I'm very grateful that funding from the Mellon Foundation on behalf of themselves, the Sloan Foundation and IMLS allowed me to spend much of the summer researching and writing a report, Emulation and Virtualization as Preservation Strategies (37-page PDF, CC-By-SA). I submitted a draft last month, it has been peer-reviewed and I have addressed the reviewers comments. It is also available on the LOCKSS web site.
I'm old enough to know better than to give a talk with live demos. Nevertheless, I'll be presenting the report at CNI's Fall membership meeting in December complete with live demos of a number of emulation frameworks. TheTL;DR executive summary of the report is below the fold.
I'm old enough to know better than to give a talk with live demos. Nevertheless, I'll be presenting the report at CNI's Fall membership meeting in December complete with live demos of a number of emulation frameworks. The
Tuesday, October 27, 2015
More interesting numbers from Backblaze
On the 17th of last month Amazon, in some regions, cut the Glacier price from 1c/GB/month to 0.7c/GB/month. It had been stable since it was announced in August 2012. As usual with Amazon, they launched at an aggressive and attractive price, and stuck there for a long time. Glacier wasn't under a lot of competitive pressure, so they didn't need to cut the price. Below the fold, I look at how Backblaze changed this.
Wednesday, October 21, 2015
ISO review of OAIS
ISO standards are regularly reviewed. In 2017, the OAIS standard ISO14721 will be reviewed. The DPC is spearheading a praiseworthy effort to involve the digital preservation community in the process of providing input to this review, via this Wiki.
I've been critical of OAIS over the years, not so much of the standard itself, but of the way it was frequently mis-used. Its title is Reference Model for an Open Archival Information System (OAIS), but it is often treated as if it were entitled The Definition of Digital Preservation, and used as a way to denigrate digital preservation systems that work in ways the speaker doesn't like by claiming that the offending system "doesn't conform to OAIS". OAIS is a reference model and, as such, defines concepts and terminology. It is the concepts and terminology used to describe a system that can be said to conform to OAIS.
Actual systems are audited for conformance to a set of OAIS-based criteria, defined currently by ISO16363. The CLOCKSS Archive passed such an audit last year with flying colors. Based on this experience, we identified a set of areas in which the concepts and terminology of OAIS were inadequate to describe current digital preservation systems such as the CLOCKSS Archive.
I was therefore asked to inaugurate the DPC's OAIS review Wiki with a post that I entitled The case for a revision of OAIS. My goal was to encourage others to post their thoughts. Please read my post and do so.
I've been critical of OAIS over the years, not so much of the standard itself, but of the way it was frequently mis-used. Its title is Reference Model for an Open Archival Information System (OAIS), but it is often treated as if it were entitled The Definition of Digital Preservation, and used as a way to denigrate digital preservation systems that work in ways the speaker doesn't like by claiming that the offending system "doesn't conform to OAIS". OAIS is a reference model and, as such, defines concepts and terminology. It is the concepts and terminology used to describe a system that can be said to conform to OAIS.
Actual systems are audited for conformance to a set of OAIS-based criteria, defined currently by ISO16363. The CLOCKSS Archive passed such an audit last year with flying colors. Based on this experience, we identified a set of areas in which the concepts and terminology of OAIS were inadequate to describe current digital preservation systems such as the CLOCKSS Archive.
I was therefore asked to inaugurate the DPC's OAIS review Wiki with a post that I entitled The case for a revision of OAIS. My goal was to encourage others to post their thoughts. Please read my post and do so.
Tuesday, October 20, 2015
Storage Technology Roadmaps
At the recent Library of Congress Storage Architecture workshop, Robert Fontana of IBM gave an excellent overview of the roadmaps for tape, disk, optical and NAND flash (PDF) storage technologies in terms of bit density and thus media capacity. His slides are well worth studying, but here are his highlights for each technology:
- Tape has a very credible roadmap out to LTO10 with 48TB/cartridge somewhere around 2022.
- Optical's roadmap shows increases from the current 100GB/disk to 200, 300, 500 and 1000GB/disk, but there are no dates on them. At least two of those increases will encounter severe difficulties making the physics work.
- The hard disk roadmap shows the slow increase in density that has prevailed for the last 4 years continuing until 2017, when it accelerates to 30%/yr. The idea is that in 2017 Heat Assisted Magnetic Recording (HAMR) will be combined with shingling, and then in 2021 Bit Patterned Media (BPM) will take over, and shortly after be combined with HAMR.
- The roadmap for NAND flash is for density to increase in the near term by 2-3X and over the next 6-8 years by 6-8X. This will require significant improvements in processing technology but "processing is a core expertise of the semiconductor industry so success will follow".
Friday, October 16, 2015
Securing WiFi routers
Via Dave Farber's IP list, I find that he, Dave Taht, Jim Gettys, the bufferbloat team, and other luminaries have submitted a response to the FCC's proposed rule-making (PDF) that would have outlawed software defined radios and open source WiFi router software such as OpenWrt. My blogging about the Internet of Things started a year ago from a conversation with Jim when he explained the Moon malware, which was scanning home routers. It subsequently turned out to be preparing to take out Sony and Microsoft's gaming networks at Christmas. Its hard to think of a better demonstration of the need for reform of the rules for home router software, but the FCC's proposal to make the only reasonably secure software for them illegal is beyond ridiculous.
The recommendations they submitted are radical but sensible and well-justified by events:
The recommendations they submitted are radical but sensible and well-justified by events:
As the submission points out, experience to date shows that vendors of home router equipment are not motivated to, do not have the skills to, and do not, maintain the security of their software. Locking down the vendor's insecure software so it can't be diagnosed or updated is a recipe for even more such disasters. The vendors don't care if their products are used in botnets or steal their customer's credentials. Forcing the vendors to use open source software and to respond in a timely fashion to vulnerability discoveries on pain of decertification is the only way to fix the problems.
- Any vendor of software-defined radio (SDR), wireless, or Wi-Fi radio must make public the full and maintained source code for the device driver and radio firmware in order to maintain FCC compliance. The source code should be in a buildable, change-controlled source code repository on the Internet, available for review and improvement by all.
- The vendor must assure that secure update of firmware be working at time of shipment, and that update streams be under ultimate control of the owner of the equipment. Problems with compliance can then be fixed going forward by the person legally responsible for the router being in compliance.
- The vendor must supply a continuous stream of source and binary updates that must respond to regulatory transgressions and Common Vulnerability and Exposure reports (CVEs) within 45 days of disclosure, for the warranted lifetime of the product, or until five years after the last customer shipment, whichever is longer.
- Failure to comply with these regulations should result in FCC decertification of the existing product and, in severe cases, bar new products from that vendor from being considered for certification.
- Additionally, we ask the FCC to review and rescind any rules for anything that conflicts with open source best practices, produce unmaintainable hardware, or cause vendors to believe they must only ship undocumented “binary blobs” of compiled code or use lockdown mechanisms that forbid user patching. This is an ongoing problem for the Internet community committed to best practice change control and error correction on safety-critical systems.
Thursday, October 15, 2015
A Pulitzer is no guarantee
Bina Venkataraman points me to Adrienne LaFrance's piece Raiders of the Lost Web at The Atlantic. It is based on an account of last month's resurrection of a 34-part, Pulitzer-winning newspaper investigation from 2007 of the aftermath of a 1961 railroad crossing accident in Colorado. It vanished from the Web when The Rocky Mountain News folded and survived only because Kevin Vaughan, the reporter, kept a copy on DVD-ROM.
Doing so likely violated copyright. Even though The Crossing was not an "orphan work":
There is a problem with the article. It correctly credits the Internet Archive with its major contribution to Web archiving, and analogizes it to the Library of Alexandria. But it fails to mention any of the other Web archives and, unlike Jill Lepore's New Yorker "Cobweb" article, doesn't draw the lesson from the analogy. Because the Library of Alexandria was by far the largest repository of knowledge in its time, its destruction was a catastrophe. The Internet Archive is by far the largest Web archive, but it is uncomfortably close to several major faults. And backing it up seems to be infeasible.
Doing so likely violated copyright. Even though The Crossing was not an "orphan work":
in 2009, the year the paper went under, Vaughan began asking for permission—from the [Denver Public] library and from E.W. Scripps, the company that owned the Rocky—to resurrect the series. After four years of back and forth, in 2013, the institutions agreed to let Vaughan bring it back to the web.Four years, plus another two to do the work. Imagine how long it would have taken had the story actually been orphaned. Vaughan also just missed another copyright problem:
With [ex-publisher John] Temple’s help, Vaughan got permission from the designer Roger Black to use Rocky, the defunct newspaper’s proprietary typeface.This is the orphan font problem that I've been warning about for the last 6 years. There is a problem with the resurrected site:
It also relied heavily on Flash, once-ubiquitous software that is now all but dead. “My role was fixing all of the parts of the website that had broken due to changes in web standards and a change of host,” said [Kevin's son] Sawyer, now a junior studying electrical engineering and computer science. “The coolest part of the website was the extra content associated with the stories... The problem with the website is that all of this content was accessible to the user via Flash.”It still is. Soon, accessing the "coolest part" of the resurrected site will require a virtual machine with a legacy browser.
There is a problem with the article. It correctly credits the Internet Archive with its major contribution to Web archiving, and analogizes it to the Library of Alexandria. But it fails to mention any of the other Web archives and, unlike Jill Lepore's New Yorker "Cobweb" article, doesn't draw the lesson from the analogy. Because the Library of Alexandria was by far the largest repository of knowledge in its time, its destruction was a catastrophe. The Internet Archive is by far the largest Web archive, but it is uncomfortably close to several major faults. And backing it up seems to be infeasible.
Wednesday, October 14, 2015
Orphan Works "Reform"
Lila Bailey at Techdirt has a post entitled Digital Orphans: The Massive Cultural Black Hole On Our Horizon about the Copyright Office's proposal for fixing the "orphan works" problem. As she points out, the proposal doesn't fix it, it just makes it different:
it doesn't once mention or consider the question of what we are going to do about the billions of orphan works that are being "born digital" every day.She represented the Internet Archive in responding to the report, so she knows whereof she writes about the born-digital user-generated content that documents today's culture:
Instead, the Copyright Office proposes to "solve" the orphan works problem with legislation that would impose substantial burdens on users that would only work for one or two works at any given time. And because that system is so onerous, the Report also proposes a separate licensing regime to support so-called "mass digitization," while simultaneously admitting that this regime would not really be appropriate for orphans (because there's no one left to claim the licensing fees). These proposals have been resoundingly criticized for many valid reasons.
We are looking down the barrel of a serious crisis in terms of society's ability to access much of the culture that is being produced and shared online today. As many of these born-digital works become separated from their owners, perhaps because users move on to newer and cooler platforms, or because the users never wanted their real identity associated with this stuff in the first place, we will soon have billions upon billions of digital orphans on our hands. If those orphans survive the various indignities that await them ... we are going to need a way to think about digital orphans. They clearly will not need to be digitized so the Copyright Office's mass digitization proposal would not apply.The born-digital "orphan works" problem is intertwined with the problems posed by the fact that much of this content is dynamic, and its execution depends on other software not generated by the user, which is both copyright and covered by an end-user license agreement, and is not being collected by the national libraries under copyright deposit legislation.
Tuesday, October 13, 2015
Access vs. Control
Hugh Rundle, in an interesting piece entitled When access isn’t even access reporting from the Australian Internet Governance Forum writes about librarians:
Worst of all, our obsession with providing access ultimately results in the loss of access. Librarians created the serials crisis because they focussed on access instead of control. The Open Access movement has had limited success because it focusses on access to articles instead of remaking the economics of academic careers. Last week Proquest announced it had gobbled up Ex-Libris, further centralising corporate control over the world’s knowledge. Proquest will undoubtedly now charge even more for their infinitely-replicable-at-negligible-cost digital files. Libraries will pay, because ‘access’. At least until they can’t afford it. The result of ceding control over journal archives has not been more access, but less.and:
As Benjamin Franklin might have said if he was a librarian: those who would give up essential liberty, to purchase a little access, deserve neither and will lose both.From the very beginning of the LOCKSS Program 17 years ago, the goal has been to provide librarians with the tools they need to take control and ownership of the content they pay for. As I write, JSTOR has been unable to deliver articles for three days and libraries all over the world have been deprived of access to all the content they have paid JSTOR for through the years. Had they owned copies of the content, as they did on paper, no such system-wide failure would have been been possible.
Friday, October 9, 2015
The Cavalry Shows Up in the IoT War Zone
Back in May I posted Time For Another IoT Rant. Since then I've added 28 comments about the developments over the last 132 days, or more than one new disaster every 5 days. Those are just the ones I noticed. So its time for another dispatch from the front lines of the IoT war zone on which I can hang reports of the disasters to come. Below the fold, I cover yesterday's happenings on two sectors of the front line.
Thursday, October 8, 2015
Two In Two Days
Tuesday, Cory Doctorow pointed to "another of [Maciej Cegłowski's] barn-burning speeches". It is entitled What Happens Next Will Amaze You and it is a must-read exploration of the ecosystem of the Web and its business model of pervasive surveillance. I commented on my post from last May Preserving the Ads? pointing to it, because Cegłowski goes into much more of the awfulness of the Web ecosystem than I did.
Yesterday Doctorow pointed to another of Maciej Cegłowski's barn-burning speeches. This one is entitled Haunted by Data, and it is just as much of a must-read. Doctorow is obviously a fan of Cegłowski's and now so am I. It is hard to write talks this good, and even harder to ensure that they are relevant to stuff I was posting in May. This one takes the argument of The Panopticon Is Good For You, also from May, and makes it more general and much clearer. Below the fold, details.
Yesterday Doctorow pointed to another of Maciej Cegłowski's barn-burning speeches. This one is entitled Haunted by Data, and it is just as much of a must-read. Doctorow is obviously a fan of Cegłowski's and now so am I. It is hard to write talks this good, and even harder to ensure that they are relevant to stuff I was posting in May. This one takes the argument of The Panopticon Is Good For You, also from May, and makes it more general and much clearer. Below the fold, details.
Tuesday, October 6, 2015
Another good prediction
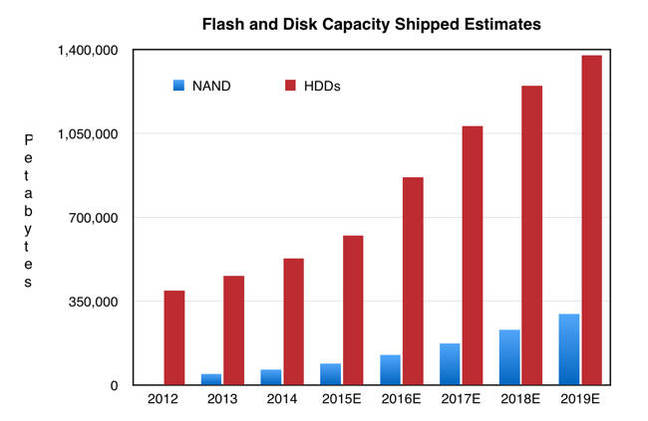
After patting myself on the back about one good prediction, here is another. Ever since Dave Anderson's presentation to the 2009 Storage Architecture meeting at the Library of Congress, I've been arguing that for flash to displace disk as the bulk storage medium would require flash vendors to make such enormous investments in new fab capacity that there would be no possibility of making an adequate return on the investments. Since the vendors couldn't make money on the investment, they wouldn't make it, and flash would not displace disk. 6 years later, despite the arrival of 3D flash that is still the case.
Chris Mellor at The Register has the story in a piece entitled Don't want to fork out for NAND flash? You're not alone. Disk still rules. Its summed up in this graph, showing the bytes shipped by flash and disk vendors.It shows that the total bytes shipped is growing rapidly, but the proportion that is flash is about stable. Flash is:
 |
| Source: Gartner & Stifel |
expected to account for less than 10 per cent of the total storage capacity the industry will need by 2020.Stifel estimates that:
Samsung is estimated to be spending over $23bn in capex on its 3D NAND for for an estimated ~10-12 exabytes of capacity.If it is fully ramped-in by 2018 it will make about 1% of what the disk manufacturers will that year. So the investment to replace that capacity would be $2.3T, which clearly isn't going to happen. Unless the investment to make a petabyte of flash per year is much less than the investment to make a petabyte of disk, disk will remain the medium of choice for bulk storage.
Sunday, October 4, 2015
Pushing back against network effects
I've had occasion to note the work of Steve Randy Waldman before. Today, he has a fascinating post up entitled 1099 as Antitrust that may not at first seem relevant to digital preservation. Below the fold I trace the important connection.
Wednesday, September 23, 2015
Canadian Government Documents
Eight years ago, in the sixth post to this blog, I was writing about the importance of getting copies of government information out of the hands of the government:
Read the article and weep.
Winston Smith in "1984" was "a clerk for the Ministry of Truth, where his job is to rewrite historical documents so that they match the current party line". George Orwell wasn't a prophet. Throughout history, governments of all stripes have found the need to employ Winston Smiths and the US government is no exception. Government documents are routinely recalled from the FDLP, and some are re-issued after alteration.Anne Kingston at Maclean's has a terrifying article, Vanishing Canada: Why we’re all losers in Ottawa’s war on data, about the Harper administration's crusade to prevent anyone finding out what is happening as they strip-mine the nation. They don't even bother rewriting, they just delete, and prevent further information being gathered. The article mentions the desperate struggle Canadian government documents librarians have been waging using the LOCKSS technology to stay ahead of the destruction for the last three years. They won this year's CLA/OCLC Award for Innovative Technology, and details of the network are here.
Read the article and weep.
Thursday, September 17, 2015
Enhancing the LOCKSS Technology
A paper entitled Enhancing the LOCKSS Digital Preservation Technology describing work we did with funding from the Mellon Foundation has appeared in the September/October issue of D-Lib Magazine. The abstract is:
The LOCKSS Program develops and supports libraries using open source peer-to-peer digital preservation software. Although initial development and deployment was funded by grants including from NSF and the Mellon Foundation, grant funding is not a sustainable basis for long-term preservation. The LOCKSS Program runs the "Red Hat" model of free, open source software and paid support. From 2007 through 2012 the program was in the black with no grant funds at all.Among the enhancements described in the paper are implementations of Memento (RFC7089) and Shibboleth, support for crawling sites that use AJAX, and some significant enhancements to the LOCKSS peer-to-peer polling protocol.
The demands of the "Red Hat" model make it hard to devote development resources to enhancements that don't address immediate user demands but are targeted at longer-term issues. After discussing this issue with the Mellon Foundation, the LOCKSS Program was awarded a grant to cover a specific set of infrastructure enhancements. It made significant functional and performance improvements to the LOCKSS software in the areas of ingest, preservation and dissemination. The LOCKSS Program's experience shows that the "Red Hat" model is a viable basis for long-term digital preservation, but that it may need to be supplemented by occasional small grants targeted at longer-term issues.
Wednesday, September 16, 2015
"The Prostate Cancer of Preservation" Re-examined
My third post to this blog, more than 8 years ago, was entitled Format Obsolescence: the Prostate Cancer of Preservation. In it I argued that format obsolescence for widely-used formats such as those on the Web, would be rare. If it ever happened, would be a very slow process allowing plenty of time for preservation systems to respond.
Thus devoting a large proportion of the resources available for preservation to obsessively collecting metadata intended to ease eventual format migration was economically unjustifiable, for three reasons. First, the time value of money meant that paying the cost later would allow more content to be preserved. Second, the format might never suffer obsolescence, so the cost of preparing to migrate it would be wasted. Third, if the format ever did suffer obsolescence, the technology available to handle it when obsolescence occurred would be better than when it was ingested.
Below the fold, I ask how well the predictions have held up in the light of subsequent developments?
Thus devoting a large proportion of the resources available for preservation to obsessively collecting metadata intended to ease eventual format migration was economically unjustifiable, for three reasons. First, the time value of money meant that paying the cost later would allow more content to be preserved. Second, the format might never suffer obsolescence, so the cost of preparing to migrate it would be wasted. Third, if the format ever did suffer obsolescence, the technology available to handle it when obsolescence occurred would be better than when it was ingested.
Below the fold, I ask how well the predictions have held up in the light of subsequent developments?
Friday, September 11, 2015
Prediction: "Security will be an on-going challenge"
The Library of Congress' Storage Architectures workshop asked gave a group of us each 3 minutes to respond to a set of predictions for 2015 and questions accumulated at previous instances of this fascinating workshop. Below the fold, the brief talk in which I addressed one of the predictions. At the last minute, we were given 2 minutes more, so I made one of my own.
Tuesday, September 8, 2015
Infrastructure for Emulation
I've been writing a report about emulation as a preservation strategy.
Below the fold, a discussion of one of the ideas that I've been thinking
about as I write, the unique position national libraries are in
to assist with building the infrastructure emulation needs to succeed.
Tuesday, August 18, 2015
Progress in solid-state memories
Last week's Storage Valley Supper Club provided an update on developments in solid state memories.
First, the incumbent technology, planar flash, has reached the end of its development path at the 15nm generation. Planar flash will continue to be the majority of flash bits shipped through 2018, but the current generation is the last.
Second, all the major flash manufacturers are now shipping 3D flash, the replacement for planar. Stacking the cells vertically provides much greater density; the cost is a much more complex manufacturing process and, at least until the process is refined, much lower yields. This has led to much skepticism about the economics of 3D flash, but it turns out that the picture isn't as bad as it appeared. The reason is, in a sense, depressing.
It always important to remember that, at bottom, digital storage media are analog. Because 3D flash is much denser, there are a lot more cells. Because of the complexity of the manufacturing process, the quality of each cell is much worse. But because there are many more cells, the impact of the worse quality is reduced. More flash controller intelligence adapting to the poor quality or even non-functionality of the individual cells, and more of the cells used for error correction, mean that 3D flash can survive lower yields of fully functional cells.
The advent of 3D means that flash prices, which had stabilized, will resume their gradual decrease. But anyone hoping that 3D will cause a massive drop will be disappointed.
Third, the post-flash solid state technologies such as Phase Change Memory (PCM) are increasingly real but, as expected, they are aiming at the expensive, high-performance end of the market. HGST has demonstrated a:
 But the big announcement was Intel/Micron's 3D XPoint. They are very cagey about the details, but it is a resistive memory technology that is 1000 times faster than NAND, 1000 times the endurance, and 100 times denser. They see the technology initially being deployed, as shown in the graph, as an ultra-fast but non-volatile layer between DRAM and flash, but it clearly has greater potential once it gets down the price curve.
But the big announcement was Intel/Micron's 3D XPoint. They are very cagey about the details, but it is a resistive memory technology that is 1000 times faster than NAND, 1000 times the endurance, and 100 times denser. They see the technology initially being deployed, as shown in the graph, as an ultra-fast but non-volatile layer between DRAM and flash, but it clearly has greater potential once it gets down the price curve.
First, the incumbent technology, planar flash, has reached the end of its development path at the 15nm generation. Planar flash will continue to be the majority of flash bits shipped through 2018, but the current generation is the last.
Second, all the major flash manufacturers are now shipping 3D flash, the replacement for planar. Stacking the cells vertically provides much greater density; the cost is a much more complex manufacturing process and, at least until the process is refined, much lower yields. This has led to much skepticism about the economics of 3D flash, but it turns out that the picture isn't as bad as it appeared. The reason is, in a sense, depressing.
It always important to remember that, at bottom, digital storage media are analog. Because 3D flash is much denser, there are a lot more cells. Because of the complexity of the manufacturing process, the quality of each cell is much worse. But because there are many more cells, the impact of the worse quality is reduced. More flash controller intelligence adapting to the poor quality or even non-functionality of the individual cells, and more of the cells used for error correction, mean that 3D flash can survive lower yields of fully functional cells.
The advent of 3D means that flash prices, which had stabilized, will resume their gradual decrease. But anyone hoping that 3D will cause a massive drop will be disappointed.
Third, the post-flash solid state technologies such as Phase Change Memory (PCM) are increasingly real but, as expected, they are aiming at the expensive, high-performance end of the market. HGST has demonstrated a:
PCM SSD with less than two microseconds round-trip access latency for 512B reads, and throughput exceeding 3.5 GB/s for 2KB block sizes.which, despite the near-DRAM performance, draws very little power.

Thursday, August 13, 2015
Authors breeding like rabbits
The Wall Street Journal points to another problem with the current system of academic publishing with an article entitled How Many Scientists Does It Take to Write a Paper? Apparently, Thousands:
 The article includes this amazing graph from Thompson-Reusters, showing the spectacular rise in papers with enough authors that their names had to reflect alphabetical order rather than their contribution to the research. And the problem is spreading:
The article includes this amazing graph from Thompson-Reusters, showing the spectacular rise in papers with enough authors that their names had to reflect alphabetical order rather than their contribution to the research. And the problem is spreading:
How long before the first paper is published with more authors than words?
In less than a decade, Dr. Aad, who lives in Marseilles, France, has appeared as the lead author on 458 scientific papers. Nobody knows just how many scientists it may take to screw in a light bulb, but it took 5,154 researchers to write one physics paper earlier this year—likely a record—and Dr. Aad led the list.
His scientific renown is a tribute to alphabetical order.

“The challenges are quite substantial,” said Marica McNutt, editor in chief of the journal Science. “The average number of authors even on a typical paper has doubled.”Of course, it is true that in some fields doing any significant research requires a large team, and that some means of assigning credit to team members is necessary. But doing so by adding their names to an alphabetized list of authors on the paper describing the results has become an ineffective way of doing the job. If each author gets 1/5154 of the credit for a good paper it is hardly worth having compared to the whole credit for a single-author bad paper. If each of the 5154 authors gets full credit, the paper generates 5145 times as much credit as it is due. And if the list is alphabetized but is treated as reflecting contribution, Dr. Aad is a big winner.
How long before the first paper is published with more authors than words?
Tuesday, August 11, 2015
Patents considered harmful
Although at last count I'm a named inventor on at least a couple of dozen US patents, I've long believed that the operation of the patent system, like the copyright system, is profoundly counter-productive. Since "reform" of these systems is inevitably hijacked by intellectual property interests, I believe that at least the patent system, if not both, should be completely abolished. The idea that an infinite supply of low-cost, government enforced monopolies is in the public interest is absurd on its face. Below the fold, some support for my position.
Friday, July 24, 2015
Amazon owns the cloud
Back in May I posted about Amazon's Q1 results, the first in which they broke out AWS, their cloud services, as a separate item. The bottom line was impressive:
AWS is very profitable: $265 million in profit on $1.57 billion in sales last quarter alone, for an impressive (for Amazon!) 17% net margin.Again via Barry Ritholtz, Re/Code reports on Q2:
Amazon Web Services, ... grew its revenue by 81 percent year on year in the second quarter. It grew faster and with higher profit margins than any other aspect of Amazon’s business.Revenue growing at 81% year-on-year at a 21% and growing margin despite:
AWS, which offers leased computing services to businesses, posted revenue of $1.82 billion, up from $1 billion a year ago, as part of its second-quarter results.
By comparison, retail sales in North America grew only 26 percent to $13.8 billion from $11 billion a year ago.
The cloud computing business also posted operating income of $391 million — up an astonishing 407 percent from $77 million at this time last year — for an operating margin of 21 percent, making it Amazon’s most profitable business unit by far. The North American retail unit turned in an operating margin of only 5.1 percent.
price competition from the likes of Google, Microsoft and IBM.Amazon clearly dominates the market, the competition is having no effect on their business. As I wrote nearly a year ago, based on Benedict Evans' analysis:
Amazon's strategy is not to generate and distribute profits, but to re-invest their cash flow into starting and developing businesses. Starting each business absorbs cash, but as they develop they turn around and start generating cash that can be used to start the next one.Unfortunately, S3 is part of AWS for reporting purposes, so we can't see the margins for the storage business alone. But I've been predicting for years that if we could, we would find them to be very generous.
Wednesday, July 15, 2015
Be Careful What You Wish For
Richard Poynder has a depressing analysis of the state of Open Access entitled HEFCE, Elsevier, the “copy request” button, and the future of open access and Bjoern Brembs has a related analysis entitled What happens to publishers that don’t maximize their profit?. They contrast vividly with the Director Zhang's vision for China's National Science Library., and Rolf Schimmer's description of the Max Planck Institute's plans. I expressed doubt that Schimmer's plan would prevent Elsevier ending up with all the money. Follow me below the fold to see how much less optimistic Brembs and Poynder are than I was.
Tuesday, July 7, 2015
IIPC Preservation Working Group
The Internet Archive has by far the largest archive of Web content but its preservation leaves much to be desired. The collection is mirrored between San Francisco and Richmond in the Bay Area, both uncomfortably close to the same major fault systems. There are partial copies in the Netherlands and Egypt, but they are not synchronized with the primary systems.
Now, Andrea Goethals and her co-authors from the IIPC Preservation Working Group have a paper entitled Facing the Challenge of Web Archives Preservation Collaboratively that reports on a survey of Web archives' preservation activities in the following areas; Policy, Access, Preservation Strategy, Ingest, File Formats and Integrity. They conclude:
Now, Andrea Goethals and her co-authors from the IIPC Preservation Working Group have a paper entitled Facing the Challenge of Web Archives Preservation Collaboratively that reports on a survey of Web archives' preservation activities in the following areas; Policy, Access, Preservation Strategy, Ingest, File Formats and Integrity. They conclude:
This survey also shows that long term preservation planning and strategies are still lacking to ensure the long term preservation of web archives. Several reasons may explain this situation: on one hand, web archiving is a relatively recent field for libraries and other heritage institutions, compared for example with digitization; on the other hand, web archives preservation presents specific challenges that are hard to meet.I discussed the problem of creating and maintaining a remote backup of the Internet Archive's collection in The Opposite of LOCKSS. The Internet Archive isn't alone in having less than ideal preservation of its collection. It's clear the major challenges are the storage and bandwidth requirements for Web archiving, and their rapid growth. Given the limited resources available, and the inadequate reliability of current storage technology, prioritizing collecting more content over preserving the content already collected is appropriate.
Tuesday, June 30, 2015
Blaming the Victim
The Washington Post is running a series called Net of Insecurity. So far it includes:
More below the fold.
- A Flaw In The Design, discussing the early history of the Internet and how the difficulty of getting it to work at all and the lack of perceived threats meant inadequate security.
- The Long Life Of A Quick 'Fix', discussing the history of BGP and the consistent failure of attempts to make it less insecure, because those who would need to take action have no incentive to do so.
- A Disaster Foretold - And Ignored, discussing L0pht and how they warned a Senate panel 17 years ago of the dangers of Internet connectivity but were ignored.
More below the fold.
Tuesday, June 23, 2015
Future of Research Libraries
Bryan Alexander reports on a talk by Xiaolin Zhang, the head of the National Science Library at the Chinese Academy of Sciences (CAS), on the future of research libraries.
Director Zhang began by surveying the digital landscape, emphasizing the ride of ebooks, digital journals, and machine reading. The CAS decided to embrace the digital-first approach, and canceled all print subscriptions for Chinese-language journals. Anything they don’t own they obtain through consortial relationships ...Below the fold, some thoughts on Director Zhang's vision.
This approach works well for a growing proportion of the CAS constituency, which Xiaolin referred to as “Generation Open” or “Generation Digital”. This group benefits from – indeed, expects – a transition from print to open access. For them, and for our presenter, “only ejournals are real journals. Only smartbooks are real books… Print-based communication is a mistake, based on historical practicality.” It’s not just consumers, but also funders who prefer open access.
Friday, June 19, 2015
EE380 talk on eBay storage

We were inspired by a 2009 paper FAWN A Fast Array of Wimpy Nodes in which David Andersen and his co-authors from C-MU showed that a network of large numbers of small CPUs coupled with modest amounts of flash memory could process key-value queries at the same speed as the networks of beefy servers used by, for example, Google, but using 2 orders of magnitude less power.

At present, eBay relies on tiering, moving data to less expensive storage such as consumer hard drives when it hasn't been accessed in some time. As I wrote last year:
Fundamentally, tiering like most storage architectures suffers from the idea that in order to do anything with data you need to move it from the storage medium to some compute engine. Thus an obsession with I/O bandwidth rather than what the application really wants, which is query processing rate. By moving computation to the data on the storage medium, rather than moving data to the computation, architectures like DAWN and Seagate's and WD's Ethernet-connected hard disks show how to avoid the need to tier and thus the need to be right in your predictions about how users will access the data.That post was in part about Facebook's use of tiering, which works well because Facebook has highly predictable data access patterns. McElroy's talk suggests that eBay's data accesses are somewhat predictable, but much less so than Facebook's. This makes his implication that tiering isn't a good long-term approach plausible.
Tuesday, June 16, 2015
Alphaville on Bitcoin
I'm not a regular reader of the Financial Times, so I really regret I hadn't noticed that Izabella Kaminska and others at the FT's Alphaville blog have been posting excellent work in their BitcoinMania series. For a taste, see Bitcoin's lien problem, in which Kaminska discusses the problems caused by the fact that the blockchain records the transfer of assets but not the conditions attached to the transfer:
Below the fold, I start from some of Kaminska's more recent work and look at another attempt to use the blockchain as a Solution to Everything.
For example, let's hypothesise that Tony Soprano was to start a bitcoin loan-sharking operation. The bitcoin network would have no way of differentiating bitcoins being transferred from his account with conditions attached - such as repayment in x amount of days, with x amount of points of interest or else you and your family get yourself some concrete boots — and those being transferred as legitimate and final settlement for the procurement of baked cannoli goods.She reports work by George K. Fogg at Perkins Coie on the legal status of Tony's claim:
Now say you've lost all the bitcoin you owe to Tony Soprano on the gambling website Satoshi Dice. What are the chances that Tony forgets all about it and offers you a clean slate? Not high. Tony, in all likelihood, will pursue his claim with you.
Indeed, given the high volume of fraud and default in the bitcoin network, chances are most bitcoins have competing claims over them by now. Put another way, there are probably more people with legitimate claims over bitcoins than there are bitcoins. And if they can prove the trail, they can make a legal case for reclamation.In other words, to avoid the lien problem you have to submit to government regulation, which is what Bitcoin was supposed to escape from. Government-regulated money comes with a government-regulated dispute resolution system. Bitcoin's lack of a dispute resolution system is seen in the problems Ross Ulbricht ran in to.
This contrasts considerably with government cash. In the eyes of the UCC code, cash doesn't take its claim history with it upon transfer. To the contrary, anyone who acquires cash starts off with a clean slate as far as previous claims are concerned. ... According to Fogg there is currently only one way to mitigate this sort of outstanding bitcoin claim risk in the eyes of US law. ... investors could transform bitcoins into financial assets in line with Article 8 of the UCC. By doing this bitcoins would be absolved from their cumbersome claim history.
The catch: the only way to do that is to deposit the bitcoin in a formal (a.k.a licensed) custodial or broker-dealer agent account.
Below the fold, I start from some of Kaminska's more recent work and look at another attempt to use the blockchain as a Solution to Everything.
Tuesday, June 9, 2015
Preserving the Ads?
Quinn Norton writes in The Hypocrisy of the Internet Journalist:
It’s been hard to make a living as a journalist in the 21st century, but it’s gotten easier over the last few years, as we’ve settled on the world’s newest and most lucrative business model: invasive surveillance. News site webpages track you on behalf of dozens of companies: ad firms, social media services, data resellers, analytics firms — we use, and are used by, them all.Georgis Kontaxis and Monica Chew won "Best Paper" at the recent Web 2.0 Security and Privacy workshop for Tracking Protection in Firefox for Privacy and Performance (PDF). They demonstrated that Tracking Protection provided:
...
I did not do this. Instead, over the years, I only enabled others to do it, as some small salve to my conscience. In fact, I made a career out of explaining surveillance and security, what the net was doing and how, but on platforms that were violating my readers as far as technically possible.
...
We can become wizards in our own right, a world of wizards, not subject to the old powers that control us now. But it’s going to take a lot of work. We’re all going to have to learn a lot — the journalists, the readers, the next generation. Then we’re going to have to push back on the people who watch us and try to control who we are.
a 67.5% reduction in the number of HTTP cookies set during a crawl of the Alexa top 200 news sites. [and] a 44% median reduction in page load time and 39% reduction in data usage in the Alexa top 200 news site.Below the fold, some details and implications for preservation:
Sunday, June 7, 2015
Brief talk at Columbia
I gave a brief talk during the meeting at Columbia on Web Archiving Collaboration: New Tools and Models to introduce the session on Tools/APIS: integration into systems and standardization. The title was "Web Archiving APIS: Why and Which?" An edited text is below the fold
Friday, June 5, 2015
Archiving games
This is just a quick note to flag two good recent posts on important but extremely difficult problem of archiving computer games. Gita Jackson at Boing-Boing in The vast, unplayable history of video games describes the importance to scholars of archiving games. Kyle Orland at Ars Technica in The quest to save today’s gaming history from being lost forever covers the technical reasons why it is so difficult in considerable detail, including quotes from many of the key players in the space.
My colleagues at the Stanford Libraries are actively working to archive games. Back in 2013, on the Library of Congress' The Signal digital preservation blog Trevor Owens interviewed Stanford's Henry Lowood, who curates our games collection.
My colleagues at the Stanford Libraries are actively working to archive games. Back in 2013, on the Library of Congress' The Signal digital preservation blog Trevor Owens interviewed Stanford's Henry Lowood, who curates our games collection.
Tuesday, June 2, 2015
Brittle systems
In my recent rant on the Internet of Things, I linked to Mike O'Dell's excellent post to Dave Farber's IP list, Internet of Obnoxious Things, and suggested you read it. I'm repeating that advice as, below the fold, I start from a different part of Mike's post.
Saturday, May 30, 2015
The Panopticon Is Good For You
As Stanford staff I get a feel-good email every morning full of stuff about the wonderful things Stanford is doing. Last Thursday's linked to this article from the medical school about Stanford's annual Big Data in Biomedicine conference. It is full of gee-whiz speculation about how the human condition can be improved if massive amounts of data is collected about every human on the planet and shared freely among medical researchers. Below the fold, I give a taste of the speculation and, in my usual way, ask what could possibly go wrong?
Thursday, May 28, 2015
Time for another IoT rant
I haven't posted on the looming disaster that is the Internet of Things You Don't Own since last October, although I have been keeping track of developments in brief comments to that post. The great Charlie Stross just weighed in with a brilliant, must-read examination of the potential the IoT brings for innovations in rent-seeking, which convinced me that it was time for an update. Below the fold, I discuss the Stross business model and other developments in the last 8 months.
Tuesday, May 26, 2015
Bad incentives in peer-reviewed science
The inability of the peer-review process to detect fraud and error in scientific publications is getting some mainstream attention. Adam Marcus and Ivan Oransky, the founders of Retraction Watch, had an op-ed in the New York Times entitled What's Behind Big Science Frauds?, in which they neatly summed up the situation:
Economists like to say there are no bad people, just bad incentives. The incentives to publish today are corrupting the scientific literature and the media that covers it. Until those incentives change, we’ll all get fooled again.Earlier this year I saw Tom Stoppard's play The Hard Problem at the Royal National Theatre, which deals with the same issue. The tragedy is driven by the characters being entranced by the prospect of publishing an attention-grabbing result. Below the fold, more on the problem of bad incentives in science.
Thursday, May 21, 2015
Unrecoverable read errors
Trevor Pott has a post at The Register entitled Flash banishes the spectre of the unrecoverable data error in which he points out that while disk manufacturers quoted Bit Error Rates (BER) for hard disks are typically 10-14 or 10-15, SSD BERs range from 10-16 for consumer drives to 10-18 for hardened enterprise drives. Below the fold, a look at his analysis of the impact of this difference of up to 4 orders of magnitude.
Tuesday, May 19, 2015
How Google Crawls Javascript
I started blogging about the transition the Web is undergoing from a document to a programming model, from static to dynamic content, some time ago. This transition has very fundamental implications for Web archiving; what exactly does it mean to preserve something that is different every time you look at it? Not to mention the vastly increased cost of ingest, because executing a program takes a lot more, a potentially unlimited amount of, computation than simply parsing a document.
The transition has big implications for search engines too; they also have to execute rather than parse. Web developers have a strong incentive to make their pages search engine friendly, so although they have enthusiastically embraced Javascript they have often retained a parse-able path for search engine crawlers to follow. We have watched academic journals adopt Javascript, but so far very few have forced us to execute it to find their content.
Adam Audette and his collaborators at Merkle | RKG have an interesting post entitled We Tested How Googlebot Crawls Javascript And Here’s What We Learned. It is aimed at the SEO (Search Engine Optimzation) world but it contains a lot of useful information for Web archiving. The TL;DR is that Google (but not yet other search engines) is now executing the Javascript in ways that make providing an alternate, parse-able path largely irrelevant to a site's ranking. Over time, this will mean that the alternate paths will disappear, and force Web archives to execute the content.
The transition has big implications for search engines too; they also have to execute rather than parse. Web developers have a strong incentive to make their pages search engine friendly, so although they have enthusiastically embraced Javascript they have often retained a parse-able path for search engine crawlers to follow. We have watched academic journals adopt Javascript, but so far very few have forced us to execute it to find their content.
Adam Audette and his collaborators at Merkle | RKG have an interesting post entitled We Tested How Googlebot Crawls Javascript And Here’s What We Learned. It is aimed at the SEO (Search Engine Optimzation) world but it contains a lot of useful information for Web archiving. The TL;DR is that Google (but not yet other search engines) is now executing the Javascript in ways that make providing an alternate, parse-able path largely irrelevant to a site's ranking. Over time, this will mean that the alternate paths will disappear, and force Web archives to execute the content.
Friday, May 15, 2015
A good op-ed on digital preservation
Bina Venkataraman was White House adviser on climate change innovation and is now at the Broad Foundation Institute working on long-term vs. short-term issues. She has a good op-ed piece in Sunday's Boston Globe entitled The race to preserve disappearing data. She and I e-mailed to and fro as she worked on the op-ed, and I'm quoted in it.
Update: Bina's affiliation corrected - my bad.
Update: Bina's affiliation corrected - my bad.
Tuesday, May 12, 2015
Potemkin Open Access Policies
Last September Cameron Neylon had an important post entitled Policy Design and Implementation Monitoring for Open Access that started:
We know that those Open Access policies that work are the ones that have teeth. Both institutional and funder policies work better when tied to reporting requirements. The success of the University of Liege in filling its repository is in large part due to the fact that works not in the repository do not count for annual reviews. Both the NIH and Wellcome policies have seen substantial jumps in the proportion of articles reaching the repository when grantees final payments or ability to apply for new grants was withheld until issues were corrected.He points out that:
Monitoring Open Access policy implementation requires three main steps. The steps are:He makes three important recommendations:
Each of these steps are difficult or impossible in our current data environment. Each of them could be radically improved with some small steps in policy design and metadata provision, alongside the wider release of data on funded outputs.
- Identify the set of outputs are to be audited for compliance
- Identify accessible copies of the outputs at publisher and/or repository sites
- Check whether the accessible copies are compliant with the policy
- Identification of Relevant Outputs: Policy design should include mechanisms for identifying and publicly listing outputs that are subject to the policy. The use of community standard persistable and unique identifiers should be strongly recommended. Further work is needed on creating community mechanisms that identify author affiliations and funding sources across the scholarly literature.
- Discovery of Accessible Versions: Policy design should express compliance requirements for repositories and journals in terms of metadata standards that enable aggregation and consistent harvesting. The infrastructure to enable this harvesting should be seen as a core part of the public investment in scholarly communications.
- Auditing Policy Implementation: Policy requirements should be expressed in terms of metadata requirements that allow for automated implementation monitoring. RIOXX and ALI proposals represent a step towards enabling automated auditing but further work, testing and refinement will be required to make this work at scale.
Thursday, May 7, 2015
Amazon's Margins
Barry Ritholtz points me to Ben Thompson's post The AWS IPO, in which he examines Amazon's most recent financials. They're the first in which Amazon has broken out AWS as a separate line of business, so they are the first to reveal the margins Amazon is achieving on their cloud business. The answer is:
AWS is very profitable: $265 million in profit on $1.57 billion in sales last quarter alone, for an impressive (for Amazon!) 17% net margin.The post starts by supposing that Amazon spun out AWS via an IPO:
One of the technology industry’s biggest and most important IPOs occurred late last month, with a valuation of $25.6 billion dollars. That’s more than Google, which IPO’d at a valuation of $24.6 billion, and certainly a lot more than Amazon, which finished its first day on the public markets with a valuation of $438 million.It concludes:
The profitability of AWS is a big deal in-and-of itself, particularly given the sentiment that cloud computing will ultimately be a commodity won by the companies with the deepest pockets. It turns out that all the reasons to believe in AWS were spot on: Amazon is clearly reaping the benefits of scale from being the largest player, and their determination to have both the most complete and cheapest offering echoes their prior strategies in e-commerce.Thompson's post is a must-read; I've only given a small taste of it. But it clearly demonstrates that even AWS overall is very profitable, let alone the profitability of S3, its storage service, which I've been blogging about for more than three years.
Tuesday, May 5, 2015
Max Planck Digital Library on Open Access
Ralf Schimmer of the Max Planck Society's Digital Library gave a fascinating presentation (PPT) as part of a panel entitled What Price Open Access at the recent CNI meeting. He, and co-authors Kai Karin Geschuhn and Andreas Vogler have now posted the paper on which it was based, Disrupting the subscription journals' business model for the necessary large-scale transformation to open access. Their argument is:
Below the fold, I look at some of the details in the paper.
All the indications are that the money already invested in the research publishing system is sufficient to enable a transformation that will be sustainable for the future. There needs to be a shared understanding that the money currently locked in the journal subscription system must be withdrawn and re-purposed for open access publishing services. The current library acquisition budgets are the ultimate reservoir for enabling the transformation without financial or other risks.They present:
generic calculations we have made on the basis of available publication data and revenue values at global, national and institutional levels.These include detailed data as to their own spending on open access article processing charges (APCs), which they have made available on-line, and from many other sources including the Wellcome Trust and the Austrian Science Fund. They show that APCs are less than €2.0K/article while subscription costs are €3.8-5.0K/article, so the claim that sufficient funds are available is credible. It is important to note that they exclude hybrid APCs such as those resulting from the stupid double-dipping deals the UK made; these are "widely considered not to reflect a true market value". As an Englishman, I appreciate under-statement. Thus they support my and Andrew Odlyzko's contention that margins in the academic publishing business are extortionate.
Below the fold, I look at some of the details in the paper.
Friday, May 1, 2015
Talk at IIPC General Assembly
The International Internet Preservation Consortium's General Assembly brings together those involved in Web archiving from around the world. This year's was held at Stanford and the Internet Archive. I was asked to give a short talk outlining the LOCKSS Program, explaining how and why it differs from most Web archiving efforts, and how we plan to evolve it in the near future to align it more closely with the mainstream of Web archiving. Below the fold, an edited text with links to the sources.
Tuesday, April 21, 2015
The Ontario Library Research Cloud
One of the most interesting sessions at the recent CNI was on the Ontario Library Research Cloud (OLRC). It is a collaboration between universities in Ontario to provide a low-cost, distributed, mutually owned private storage cloud with adequate compute capacity for uses such as text-mining. Below the fold, my commentary on their presentations.
Tuesday, April 14, 2015
The Maginot Paywall
Two recent papers examine the growth of peer-to-peer sharing of journal articles.
Guilliame Cabanac's Bibliogifts in LibGen? A study of a text-sharing platform driven by biblioleaks and crowdsourcing (LG) is a statistical study of the Library Genesis service,
and Carolyn Caffrey Gardner and Gabriel J. Gardner's Bypassing Interlibrary Loan via Twitter: An Exploration of #icanhazpdf Requests (TW) is a similar study of one of the sources for Library Genesis.
Both implement forms of Aaron Swartz's Guerilla Open Access Manifesto, a civil disobedience movement opposed to the malign effects of current copyright law on academic research.
Below the fold,
some thoughts on the state of this movement.
Friday, April 10, 2015
3D Flash - not as cheap as chips
Chris Mellor has an interesting piece at The Register pointing out that while 3D NAND flash may be dense, its going to be expensive.
The reason is the enormous number of processing steps per wafer -
between 96 and 144 deposition layers for the three leading 3D NAND flash
technologies. Getting non-zero yields from that many steps involves
huge investments in the fab:
PS - "as cheap as chips" is a British usage.
Chris has this chart, from Gartner and Stifel, comparing the annual capital expenditure per TB of storage of NAND flash and hard disk. Each TB of flash contains at least 50 times as much capital as a TB of hard disk, which means it will be a lot more expensive to buy.Samsung, SanDisk/Toshiba, and Micron/Intel have already announced +$18bn investment for 3D NAND.
This compares with Seagate and Western Digital’s capex totalling ~$4.3 bn over the past three years.
- Samsung’s new Xi’an, China, 3D NAND fab involves a +$7bn total capex outlay
- Micron has outlined a $4bn spend to expand its Singapore Fab 10

{kind=link}
PS - "as cheap as chips" is a British usage.
Wednesday, April 8, 2015
Trying to fix the symptoms
In response to many complaints that the peer review process was so slow that it was impeding scientific progress, Nature announced that they would allow authors to pay to jump the queue:
As of 24th March 2015, a selection of authors submitting a biology manuscript to Scientific Reports will be able to opt-in to a fast-track peer-review service at an additional cost. Authors who opt-in to fast-track will receive an editorial decision (accept, reject or revise) with peer-review comments within three weeks of their manuscript passing initial quality checks.It is true that the review process is irritatingly slow, but this is a bad idea on many levels. Such a bad idea that an editorial board member resigned in protest. Below the fold I discuss some of the levels.
Sunday, April 5, 2015
The Mystery of the Missing Dataset
I was interviewed for an upcoming news article in Nature about the problem of link rot in scientific publications, based on the recent Klein et al paper in PLoS One. The paper is full of great statistical data but, as would be expected in a scientific paper, lacks the personal stories that would improve a news article.
I mentioned the interview over dinner with my step-daughter, who was featured in the very first post to this blog when she was a grad student. She immediately said that her current work is hamstrung by precisely the kind of link rot Klein et al investigated. She is frustrated because the dataset from a widely cited paper has vanished from the Web. Below the fold, a working post that I will update as the search for this dataset continues.
I mentioned the interview over dinner with my step-daughter, who was featured in the very first post to this blog when she was a grad student. She immediately said that her current work is hamstrung by precisely the kind of link rot Klein et al investigated. She is frustrated because the dataset from a widely cited paper has vanished from the Web. Below the fold, a working post that I will update as the search for this dataset continues.
Wednesday, April 1, 2015
Preserving Long-Form Digital Humanities
Carl Straumsheim at Inside Higher Ed reports on a sorely-needed new Mellon Foundation initiative supporting digital publishing in the humanities:
The Andrew W. Mellon Foundation is aggressively funding efforts to support new forms of academic publishing, which researchers say could further legitimize digital scholarship.Note in particular:
The foundation in May sent university press directors a request for proposals to a new grant-making initiative for long-form digital publishing for the humanities. In the e-mail, the foundation noted the growing popularity of digital scholarship, which presented an “urgent and compelling” need for university presses to publish and make digital work available to readers.
The foundation’s proposed solution is for groups of university presses to ... tackle any of the moving parts that task is comprised of, including “...(g) distribution; and (h) maintenance and preservation of digital content.”Below the fold, some thoughts on this based on experience from the LOCKSS Program.
Tuesday, March 24, 2015
The Opposite Of LOCKSS
Jill Lepore's New Yorker "Cobweb" article has focused attention on the importance of the Internet Archive, and the analogy with the Library of Alexandria. In particular on the risks implicit in the fact that both represent single points of failure because they are so much larger than any other collection.
Typically, Jason Scott was first to respond with a outline proposal to back up the Internet Archive, by greatly expanding the collaborative efforts of ArchiveTeam. I think Jason is trying to do something really important, and extremely difficult.
The Internet Archive's collection is currently around 15PB. It has doubled in size in about 30 months. Suppose it takes another 30 months to develop and deploy a solution at scale. We're talking crowd-sourcing a distributed backup of at least 30PB growing at least 3PB/year.
To get some idea of what this means, suppose we wanted to use Amazon's Glacier. This is, after all, exactly the kind of application Glacier is targeted at. As I predicted shortly after Glacier launched, Amazon has stuck with the 1c/GB/mo price. So in 2017 we'd be paying Amazon $3.6M a year just for the storage costs. Alternately, suppose we used Backblaze's Storage Pod 4.5 at their current price of about 5c/GB, for each copy we'd have paid $1.5M in hardware cost and be adding $150K worth per year. This ignores running costs and RAID overhead.
It will be very hard to crowd-source resources on this scale, which is why I say this is the opposite of Lots Of Copies Keep Stuff Safe. The system is going to be short of storage; the goal of a backup for the Internet Archive must be the maximum of reliability for the minimum of storage.
Nevertheless, I believe it would be well worth trying some version of his proposal and I'm happy to help any way I can. Below the fold, my comments on the design of such a system.
Typically, Jason Scott was first to respond with a outline proposal to back up the Internet Archive, by greatly expanding the collaborative efforts of ArchiveTeam. I think Jason is trying to do something really important, and extremely difficult.
The Internet Archive's collection is currently around 15PB. It has doubled in size in about 30 months. Suppose it takes another 30 months to develop and deploy a solution at scale. We're talking crowd-sourcing a distributed backup of at least 30PB growing at least 3PB/year.
To get some idea of what this means, suppose we wanted to use Amazon's Glacier. This is, after all, exactly the kind of application Glacier is targeted at. As I predicted shortly after Glacier launched, Amazon has stuck with the 1c/GB/mo price. So in 2017 we'd be paying Amazon $3.6M a year just for the storage costs. Alternately, suppose we used Backblaze's Storage Pod 4.5 at their current price of about 5c/GB, for each copy we'd have paid $1.5M in hardware cost and be adding $150K worth per year. This ignores running costs and RAID overhead.
It will be very hard to crowd-source resources on this scale, which is why I say this is the opposite of Lots Of Copies Keep Stuff Safe. The system is going to be short of storage; the goal of a backup for the Internet Archive must be the maximum of reliability for the minimum of storage.
Nevertheless, I believe it would be well worth trying some version of his proposal and I'm happy to help any way I can. Below the fold, my comments on the design of such a system.
Tuesday, March 17, 2015
More Is Not Better
Hugh Pickens at /. points me to Attention decay in science, providing yet more evidence that the way the journal publishers have abdicated their role as gatekeepers is causing problems for science. The abstract claims:
The exponential growth in the number of scientific papers makes it increasingly difficult for researchers to keep track of all the publications relevant to their work. Consequently, the attention that can be devoted to individual papers, measured by their citation counts, is bound to decay rapidly. ... The decay is ... becoming faster over the years, signaling that nowadays papers are forgotten more quickly. However, when time is counted in terms of the number of published papers, the rate of decay of citations is fairly independent of the period considered. This indicates that the attention of scholars depends on the number of published items, and not on real time.Below the fold, some thoughts.
Friday, March 13, 2015
Journals Considered Even More Harmful
Two years ago I posted Journals Considered Harmful, based on this excellent paper which concluded that:
The current empirical literature on the effects of journal rank provides evidence supporting the following four conclusions: 1) Journal rank is a weak to moderate predictor of scientific impact; 2) Journal rank is a moderate to strong predictor of both intentional and unintentional scientific unreliability; 3) Journal rank is expensive, delays science and frustrates researchers; and, 4) Journal rank as established by [Impact Factor] violates even the most basic scientific standards, but predicts subjective judgments of journal quality.
Subsequent events justify skepticism about the net value journals add after allowing for the value they subtract. Now the redoubtable Eric Hellman points out another value-subtracted aspect of the journals with his important post entitled 16 of the top 20 Research Journals Let Ad Networks Spy on Their Readers. Go read it and be appalled.
Update: Eric very wisely writes:
Update: Eric very wisely writes:
I'm particularly concerned about the medical journals that participate in advertising networks. Imagine that someone is researching clinical trials for a deadly disease. A smart insurance company could target such users with ads that mark them for higher premiums. A pharmaceutical company could use advertising targeting researchers at competing companies to find clues about their research directions. Most journal users (and probably most journal publishers) don't realize how easily online ads can be used to gain intelligence as well as to sell products.I should have remembered that, less than 3 weeks ago, Brian Merchant at Motherboard posted Looking Up Symptoms Online? These Companies Are Tracking You, pointing out that health sites such as WebMD and, even less forgivably, the Centers for Disease Control, are rife with trackers selling their visitors' information to data brokers:
The CDC example is notable because it’s a government site, one we assume should be free of the profit motive, and entirely safe for use. “It’s basically negligence,”If you want to look up health information online, you need to use Tor.
Thursday, March 12, 2015
Google's near-line storage offering
Yesterday, Google announced the beta of their Nearline Storage offering. It has the same 1c/GB/mo pricing as Amazon's Glacier, but it has three significant differences:
I believe I know how Google has built their nearline technology, I wrote about it two years ago.
- It claims to have much lower latency, a few seconds instead of a few hours.
- It has the same (synchronous) API as Google's more expensive storage, where Glacier has a different (asynchronous) API than S3.
- Its pricing for getting data out lacks Glacier's 5% free tier, but otherwise is much simpler than Glacier's.
I believe I know how Google has built their nearline technology, I wrote about it two years ago.
Thursday, March 5, 2015
Archiving Storage Tiers
Tom Coughlin uses Hetzler's touch-rate metric to argue for tiered storage for archives in a two-part series. Although there's good stuff there, I have two problems with Tom's argument. Below the fold, I discuss them.
Tuesday, March 3, 2015
IDCC15
I wasn't able to attend IDCC2015 two weeks ago in London, but I've been catching up with the presentations on the Web. Below the fold, my thoughts on a few of them.
Subscribe to:
Posts (Atom)