From my continuing series on the dismal outlook for Kryder's Law,
The Register reports on the continuing impact of the Thai floods:
Hard disk drive prices are unlikely to return to pre-flood levels until
2014 despite rising production levels, thanks to surging demand, vendor
lock-in and a market dominated by just two suppliers, according to
analysts.
Had there been no floods, and had the industry managed even just the
20%/yr increase in bit density that is now projected, and had margins remained stable instead of
increasing dramatically,
prices in 2014 would have been about 1/2 their pre-flood levels. So,
three years later, costs will be at least double what would have been
predicted before the floods.
More recent reports suggest that
Western Digital is recovering somewhat better than was expected:
Keene said WD had "recovered" more quickly than industry commentators had forecast – the plants were nearing full capacity some months ago – and said only some high-spec products remained in tight supply.
while
Seagate is having greater difficulty:
Seagate will miss its fourth quarter's sales target as its competitors recover faster than expected from floods that knackered hard drive supplies.
As part of a feature series on the solid state storage revolution, Ars Technica has a
useful overview of the future of SSDs., with a clear explanation of why shrinking the flash cell size reduces not just the data retention time but also the number of write cycles a cell can sustain, and why moving from MLC (2 bits per cell) to TLC (3 bits per cell) makes the problems even worse. The article describes the
contortions flash controller makers are going through to mitigate these problems, which are starting to sound like those the hard disk makers are struggling with. The article is suitably sceptical about the prospects for alternative solid state memories, but moderately enthusiastic about memristors. This is good news because:
a significant number of folks who have suffered through SSD failure have
so suffered not because the flash wore out, but rather because of an
actual component failure—a flash chip died, say, or the controller died.
Component failure can occur in any device, and if memristor-based
drives are eventually manufactured and assembled in the same plants by
the same companies who make today's HDDs and SSDs—and we have every
reason to believe they will be—then a memristor-based storage drive with
a million-write endurance rating would likely be effectively immortal.
Other components are likely to fail long before the storage medium
reaches its write endurance limit.
The Register hits some of the same points and
teases out some of the business implications:
There are several post-NAND technologies jostling for prominence,
such as Phase-change memory, resistive RAM, memristors and IBM's
Racetrack memory. All promise greater capacity, higher speed and longer
endurance than flash. It's not clear which one of them will become the
non-volatile memory follow-on from NAND, but, whichever it is, the
controller software crafter to cope with NAND inadequacies won't be
needed.
MLC NAND wear-levelling and write amplification reduction technology
won't be needed. The NAND signal processing may be irrelevant. Garbage
collection could be completely different. Entire code stacks will need
to be re-written. All the flash array and hybrid flash/disk startups
will find their software IP devalued and their business models at risk
from post-NAND startup's IP with products offering longer life and
faster-performance.
One solid state storage technology wasn't included in these reviews because it was only announced July 10. Karlsruhe Institute of Technology managed to build a memristor-like 1-bit device using only 51 atoms:
They point out that a bit on a hard disk drive uses about 3 million
atoms while their molecule has just 51 atoms inside it, including the
single iron atom they've inserted at its centre. Wow, that's 58,823.5
times denser, say 50,000X for argument's sake, which would mean a 4TB
hard drive could store 200PB using molecular bit storage. - except that it couldn't ... If molecular bit storage is ever going to be used, it will be in
solid state storage and you will still need to access the bits – with
one wire to deliver the electric pulse to set them and another wire to
sense their setting. Even using nanowires, more space in the device
would be taken up by circuitry than by storage.
At Slashdot,
Lucas123 describes how hybrid drives, the compromise between SSDs and hard disks, which add a small amount of solid state storage to a normal hard drive, do not in fact deliver the advantages of both with the disadvantages of neither and so are not succeeding in the market:
New numbers show hybrid drives, which combine NAND flash with
spinning disk, will double in sales from 1 million to 2 million units
this year. Unfortunately for Seagate — the only manufacturer of hybrids —
solid-state drive sales are expected to hit 18 million units
this year and 69 million by 2016. ... If hybrid drives are to have a
chance at surviving, more manufacturers will need to produce them, and
they'll need to come in thinner form factors to fit today's ultrabook
laptops.
The Register reports on a
briefing on disk technology futures from Western Digital, which repeated
Dave Anderson of Seagate's (PDF) 2009 point that there is no feasible alternative to disks in the medium term:
The demand for HDD capacity continues unabated as there is no
alternative whatsoever for fast access to online data; NAND flash fabs
are in short supply and have a long lead time. In 2011, 70 per cent of
all the shipped petabytes were HDDs, with optical, tape, NAND and DRAM
making up the rest. Some 350,000PB of disk were shipped, compared to
about 20,000 PB of NAND.
WD's COO, Tim Leyden, reckons another 40 NAND fabs would be needed to
make 350K PB of NAND, and that would cost $400bn at $10bn/fab capable
of shipping 8.8K PB/year. It isn't going to happen any time soon.
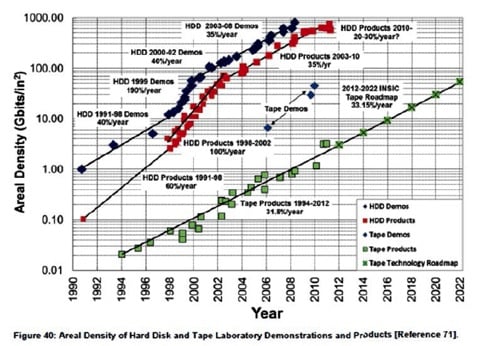
Here is WD's version of the Kryder's Law curve, on a scale that minimises the slowing from 40%/yr to 20%/yr in the last few years, and they play that down as temporary in words too:
WD says that HDD areal density growth has slowed from an annual 40 per
cent compound annual growth rate to just 20 per cent as the current PMR
recording technology nears its maximum efficacy, with a transition to
energy-assisted magnetic recording (EAMR) coming and representing the
possibility of regaining the 40 per cent rate.
But they are clearly concerned enough to raise the possibility of adding platters (and thus cost):
Our contact said that 5-platter 3.5-inch drives were a possibility.
With a trend towards thin and light drives for Ultrabooks, the possibility of platter addition is denied in this market sector.
The decreasing proportion of the market occupied by PCs that use 3.5" drives is clear from this graph from Forester Research. The competition is not just laptops, netbooks and tablets but also
smartphones:
Vendors shipped close to 489 million smartphones in 2011, compared
to 415 million PCs. Smartphone shipments increased by 63% over the
previous year, compared to 15% growth in PC shipments.
Canalys includes pad or tablet computers in its PC category
calculation, and this was the growth area in PCs. Pad shipments grew by
274% over the past year. Pads accounted for 15% of all client PC
shipments. Desktops grew by only two percent over the past year, and
notebooks by seven percent.
Finally, on June 29th at the height of the "derecho" storm affecting the DC area,
Amazon's cloud suffered an outage:
An Amazon Web Services data center in northern Virginia lost power Friday night during an electrical storm, causing downtime for numerous customers — including Netflix,
which uses an architecture designed to route around problems at a
single availability zone. The same data center suffered a power outage two weeks ago and had connectivity problems earlier on Friday.
Many of Amazon's customers were impacted:
Netflix, Pinterest, Instagram, and Heroku, which run their services atop
Amazon's infrastructure cloud, all reported outages because of the
power failure.
Amazon produced their
characteristically informative post-mortem on the event, which explained the cause:
At 7:24pm PDT, a large voltage spike was
experienced by the electrical switching equipment in two of the US
East-1 datacenters supporting a single Availability Zone. ... In one of the datacenters, the transfer completed without
incident. In the other, the generators started successfully, but each
generator independently failed to provide stable voltage as they were
brought into service. ... servers operated without interruption during this period on the
Uninterruptable Power Supply (“UPS”) units. Shortly thereafter,
utility power was restored ... The utility power in the Region
failed a second time at 7:57pm PDT. Again, all rooms of this one
facility failed to successfully transfer to generator power ... all servers continued to operate normally on ... UPS ... power. ... the UPS systems
were depleting and servers began losing power at 8:04pm PDT. Ten minutes
later, the backup generator power was stabilized, the UPSs were
restarted, and power started to be restored by 8:14pm PDT. At 8:24pm
PDT, the full facility had power to all racks. ... Approximately 7% of the EC2 instances in the US-EAST-1 Region were ... impacted by the power loss. ... The vast majority of these
instances came back online between 11:15pm PDT and just after midnight.
Time for the completion of this recovery was extended by a bottleneck
in our server booting process. ... The majority of EBS
servers had been brought up by 12:25am PDT on Saturday. ... By 2:45am PDT, 90% of outstanding volumes had been turned
over to customers. We have identified several areas in the recovery
process that we will further optimize to improve the speed of processing
recovered volumes.
They also provided detailed descriptions of the mechanisms that caused the customer impacts, which should be required reading for anyone building reliable services.


{kind=link}