One difficulty was that although academic journals contained some of the Web content that was most important to preserve for the future, the Internet Archive could not access them because they were paywalled. Two years later, Vicky Reich and I started the LOCKSS (Lots Of Copies Keep Stuff Safe) program to address this problem. In 2000's Permanent Web Publishing we wrote:
Librarians have a well-founded confidence in their ability to provide their readers with access to material published on paper, even if it is centuries old. Preservation is a by-product of the need to scatter copies around to provide access. Librarians have an equally well-founded skepticism about their ability to do the same for material published in electronic form. Preservation is totally at the whim of the publisher.Now, Jeffrey Brainard's Dozens of scientific journals have vanished from the internet, and no one preserved them and Diana Kwon's More than 100 scientific journals have disappeared from the Internet draw attention to this long-standing problem. Below the fold I discuss the paper behind the Science and Nature articles.
A subscription to a paper journal provides the library with an archival copy of the content. Subscribing to a Web journal rents access to the publisher's copy. The publisher may promise "perpetual access", but there is no business model to support the promise. Recent events have demonstrated that major journals may vanish from the Web at a few months notice.
This poses a problem for librarians, who subscribe to these journals in order to provide both current and future readers with access to the material. Current readers need the Web editions. Future readers need paper; there is no other way to be sure the material will survive.
Brainard writes:
Eighty-four online-only, open-access (OA) journals in the sciences, and nearly 100 more in the social sciences and humanities, have disappeared from the internet over the past 2 decades as publishers stopped maintaining them, potentially depriving scholars of useful research findings, a study has found.The preprint he refers to is Open is not forever: a study of vanished open access journals by Mikael Laakso, Lisa Matthias and Najko Jahn. Their abstract reads:
An additional 900 journals published only online also may be at risk of vanishing because they are inactive, says a preprint posted on 3 September on the arXiv server. The number of OA journals tripled from 2009 to 2019, and on average the vanished titles operated for nearly 10 years before going dark, which “might imply that a large number … is yet to vanish,” the authors write.
The preservation of the scholarly record has been a point of concern since the beginning of knowledge production. With print publications, the responsibility rested primarily with librarians, but the shift towards digital publishing and, in particular, the introduction of open access (OA) have caused ambiguity and complexity. Consequently, the long-term accessibility of journals is not always guaranteed, and they can even disappear from the web completely. The purpose of this exploratory study is to systematically study the phenomenon of vanished journals, something that has not been done before. For the analysis, we consulted several major bibliographic indexes, such as Scopus, Ulrichsweb, and the Directory of Open Access Journals, and traced the journals through the Internet Archive’s Wayback Machine. We found 176 OA journals that, through lack of comprehensive and open archives, vanished from the web between 2000–2019, spanning all major research disciplines and geographic regions of the world. Our results raise vital concern for the integrity of the scholarly record and highlight the urgency to take collaborative action to ensure continued access and prevent the loss of more scholarly knowledge. We encourage those interested in the phenomenon of vanished journals to use the public dataset for their own research.The preprint provides an excellent overview of the state of formal preservation efforts for open access journals, and what I expect will be an invaluable dataset for future work. But this isn't news, see for example the 2014 overview in The Half-Empty Archive.
We and others have been taking "collaborative action to ensure continued access and prevent the loss of more scholarly knowledge" for more than two decades. I covered the early history of this effort in 2011's A Brief History of E-Journal Preservation. In particular, the "long tail" of smaller, open-access journals, especially non-English ones, has been a continuing concern:
Over the years, the LOCKSS team have made several explorations of the long tail. Among these were a 2002 meeting of humanities librarians that identified high-risk content such as World Haiku Review and Exquisite Corpse, and work funded by the Soros Foundation with South African librarians that identified fascinating local academic journals in fields such as dry-land agriculture and AIDS in urban settings. Experience leads to two conclusions:What have we learned in the last two decades that illuminates the work of Laakso et al? First, they write:
Both were part of the motivation behind the LOCKSS Program's efforts to implement National Hosting networks.
- Both subject and language knowledge is important to identifying the worthwhile long-tail content.
- Long-tail content in English is likely to be open access; in other languages much more is subscription.
While all digital journals are subject to the same threats, OA journals face unique challenges. Efforts around preservation and continued access are often aimed at securing postcancellation access to subscription journals—content the library has already paid for. The same financial incentives do not exist when journals are freely available.Two decades ago the proportion of open access journals was very low. Our approach to marketing journal preservation to librarians was to treat it as "subscription insurance":
Libraries have to trade off the cost of preserving access to old material against the cost of acquiring new material. They tend to favor acquiring new material. To be effective, subscription insurance must cost much less than the subscription itself.Even though we managed to keep the cost of participating in the distributed LOCKSS program very low, relatively few libraries opted in. A greater, but still relatively small proportion of libraries opted into the centralized Portico archive. Doing so involved simply signing a check, as opposed to the LOCKSS program that involved signing a smaller check plus actually running a LOCKSS box. Nevertheless, as I wrote in 2011:
Despite these advantages, Portico has failed to achieve economic sustainability on its own. As Bill Bowen said discussing the Blue Ribbon Task Force Report:Thus we have:"it has been more challenging for Portico to build a sustainable model than parts of the report suggest."Libraries proved unwilling to pay enough to cover its costs. It was folded into a single organization with JSTOR, in whose $50M+ annual cash flow Portico's losses could be buried.
Lesson 1: libraries won't pay enough to preserve even subscription content, let alone open-access content.
 This is understandable because libraries, even national libraries, have been under sustained budget pressure for many years:
This is understandable because libraries, even national libraries, have been under sustained budget pressure for many years:The budgets of libraries and archives, the institutions tasked with acting as society's memory, have been under sustained attack for a long time. ... I drew this graph of the British Library's annual income in real terms (year 2000 pounds). It shows that the Library's income has declined by almost 45% in the last decade.The budget pressures are exacerbated by the inexorable rise of the subscriptions libraries must pay to keep the stockholders of the oligopoly academic publishers happy. Their content is not at risk; Elsevier (founded 1880) is not going away, nor is the content that keeps them in business.
Memory institutions that can purchase only half what they could 10 years ago aren't likely to greatly increase funding for acquiring new stuff; it's going to be hard for them just to keep the stuff (and the staff) they already have.
The participants in the academic publishing ecosystem with the money and the leverage are the government and philanthropic funders. Laasko et al write:
Over the last decade, an increasing number of research funders have implemented mandates that require beneficiaries to ensure OA to their publications by either publishing in OA journals or, when choosing subscription journals, depositing a copy of the manuscript in an OA repository. In addition, many of these mandates also require publications to be deposited in a repository when publishing in OA journals to secure long-term access.... Recently, coalitions S has proposed a rather radical stance on preservation, which requires authors to only publish in journals with existing preservation arrangements. If implemented, such a mandate would prevent authors from publishing in the majority of OA journals indexed in the DOAJ (10,011 out of 14,068; DOAJ, 2019).Note that funders are mandating both open access and preservation, without actually funding the infrastructure that make both possible.
Even if funding were available for preserving open-access journals, how would the at-risk journals be identified? In the days of paper journals, librarians were in the path between scholars and the articles they needed, both because the librarians needed to know which journals to pay for, and the scholars needed help finding the relevant journals. The evolution of the Web has largely removed them from this path. Scholars access the articles they need not via the journal, but via general (Google) or specialized (Google Scholar) search engines. Thus librarians' awareness of the universe of journals has atrophied. Note the difficulties Laakso et al had in identifying open-access journals that had died:
A journal-level approach, on the other hand, is challenging because no single data source exists that tracks the availability and accessibility of journals over time. Large indexes, for example, primarily hold records of active journals, and journal preservation services only maintain records of participating journals. To solve this problem and to create a dataset that is as comprehensive as possible, we consulted several different data sources—title lists by the DOAJ, Ulrichsweb, Scopus title lists, and previously created datasets that might point to vanished OA journals ... We collected the data manually, and each data source required a unique approach for detecting potential vanished journalsThus we have:
Lesson 2: No-one, not even librarians, knows where most of the at-risk open-access journals are.None of the human participants (authors, reviewers, publishers, librarians, scholars) in the journal ecosystem places a priority on preservation, and the funds available per-journal are scarce. Thus human intervention in the preservation process must be eliminated, both because it is unafforable and it is error-prone.
Thus we have:
Lesson 3: The production preservation pipeline must be completely automated.Just as with Web archiving in general, e-journal preservation is primarily an economic problem. There is way too much content per dollar of budget. The experience of the traditional e-journal preservation systems shows that ingest, and in particular quality assurance is the most expensive part of the system, because it is human-intensive. There is a trade-off between quality and quantity. If quality is prioritized, resources will flow to the high-profile journals that are at lower risk. Lesson 3 shows that effective preservation systems have to be highly automated, trading quality for quantity. This is the only way to preserve the lower-profile, high-risk content.
Thus we have:
Lesson 4: Don't make the best be the enemy of the good. I.e. get as much as possible with the available funds, don't expect to get everything.Based on this experience, Vicky and I decided that, since traditional efforts were not preserving the at-risk content, we needed to try something different. Last February, I posted The Scholarly Record At The Internet Archive describing this new approach:
The Internet Archive has been working on a Mellon-funded grant aimed at collecting, preserving and providing persistent access to as much of the open-access academic literature as possible. The motivation is that much of the "long tail" of academic literature comes from smaller publishers whose business model is fragile, and who are at risk of financial failure or takeover by the legacy oligopoly publishers. This is particularly true if their content is open access, since they don't have subscription income. This "long tail" content is thus at risk of loss or vanishing behind a paywall.Although they are both focused on the open-access literature, note the key differences between this and the traditional approaches assessed by Laakso et al:
The project takes two opposite but synergistic approaches:
- Top-Down: Using the bibliographic metadata from sources like CrossRef to ask whether that article is in the Wayback Machine and, if it isn't trying to get it from the live Web. Then, if a copy exists, adding the metadata to an index.
- Bottom-up: Asking whether each of the PDFs in the Wayback Machine is an academic article, and if so extracting the bibliographic metadata and adding it to an index.
- The focus is on preserving articles, not journals. This makes sense because the evolution of the Web means that the way scholars access articles is no longer via the journal, but via links and searches directly to the individual article.
- Neither librarians nor publishers are involved in identifying content for preservation. It is found via the normal Web crawling technique of following links to a page, extracting the links on that page, and following them in turn.
- Neither libraries nor publishers are involved in funding preservation. Because the processes at the Internet Archive are entirely automated, their cost increment in production over the Web crawling that the Internet Archive already does is small. Thus the preservation effort is economically sustainable, it is a byproduct of the world's premier Web archiving program.
 |
| Source |
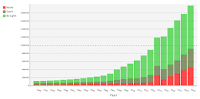
Of the 14.8 million known open access articles published since 1996, the Internet Archive has archived, identified, and made available through the Wayback Machine 9.1 million of them (“bright” green in the chart above). In the jargon of Open Access, we are counting only “gold” and “hybrid” articles which we expect to be available directly from the publisher, as opposed to preprints, such as in arxiv.org or institutional repositories. Another 3.2 million are believed to be preserved by one or more contracted preservation organizations, based on records kept by Keepers Registry (“dark” olive in the chart). These copies are not intended to be accessible to anybody unless the publisher becomes inaccessible, in which case they are “triggered” and become accessible.The difficulties Newbold refers to are mostly the normal "difficulties" encountered in crawling the Web, 404s, paywalls, server outages, etc. Despite the difficulties, and the limited resources available, this effort has collected and preserved 61% of the known open access articles, where the formal preservation efforts have collected and preserved 22%.
This leaves at least 2.4 million Open Access articles at risk of vanishing from the web (“None”, red in the chart). While many of these are still on publisher’s websites, these have proven difficult to archive.
You can both access and contribute to the results of this effort:
we built an editable catalog (https://fatcat.wiki) with an open API to allow anybody to contribute. As the software is free and open source, as is the data, we invite others to reuse and link to the content we have archived. We have also indexed and made searchable much of the literature to help manage our work and help others find if we have archived particular articles. We want to make scholarly material permanently available, and available in new ways– including via large datasets for analysis and “meta research.”Arguably, the Internet Archive is inadequate as a preservation service, for two reasons:
- Storage reliability. There are two issues. First, the Archive maintains two full replicas of its 45+ petabytes of content, plus some partial replicas. Technically, two replicas is not enough for safety. But the Archive is so big that maintaining a replica is a huge cost, enough that a third would break the budget. Second, as I discussed in A Petabyte For A Century, the combination of huge scale and long timeframe places datasets the size of the Archive's beyond our ability to ensure perfect storage.
- Format obsolescence. In 1995 Jeff Rothenberg wrote an article in Scientific American that first drew public attention to the fact that digital media have none of the durable properties of paper. But his focus was not on "bit-rot" but on the up-to-then rapid obsolescence of digital formats. This has remained a major concern among digital preservationists ever since but, as I have been pointing out since 2007, it is overblown. Firstly, formats on the Web are in effect network protocols, the most stable standards in the digital domain. Research shows the rate of obsolescence is extremely slow. Secondly, if preserved Web formats ever do become obsolete, we have two different viable techniques to render them; the LOCKSS Program demonstrated Transparent Format Migration of Preserved Web Content in 2005, and Ilya Kreymer's oldweb.today shows how they can be rendered using preserved browsers.
the Internet Archive’s Wayback Machine once again proved to be an invaluable tool, which enabled us to access the journal websites, or most often fragments thereof, and record the year of the last published OA issue and when the journal was last available online.Again, it is important to focus on preserving the articles, not the journals, which these days are relevant to scholars only as an unreliable quality tag. Many of the articles from Laakso et al's "vanished journals" are already preserved, however imperfectly, by the Internet Archive. Improving the process that collects and identifies such articles, as the Archive is already doing, is a much more fruitful approach than:
...
The Internet Archive, and especially the Wayback Machine, have proven to be invaluable resources for this research project since following the traces of vanished journals would have been much more uncertain and imprecise otherwise. In some cases, the Internet Archive also saves cached snapshots of individual articles, so they remain accessible, yet the snapshots do not necessarily amount to complete journal volumes
collaborative action in preserving digital resources and preventing the loss of more scholarly knowledgewhich is the approach that, over the past two decades, has proven to be inadequate to the task.
3 comments:
Mark Graham's Cloudflare and the Wayback Machine, joining forces for a more reliable Web announces yet another source of URLs for the Wayback Machine:
"We archive URLs that are identified via a variety of different methods, such as “crawling” from lists of millions of sites, as submitted by users via the Wayback Machine’s “Save Page Now” feature, added to Wikipedia articles, referenced in Tweets, and based on a number of other “signals” and sources, such multiple feeds of “news” stories.
An additional source of URLs we will preserve now originates from customers of Cloudflare’s Always Online service. As new URLs are added to sites that use that service they are submitted for archiving to the Wayback Machine. In some cases this will be the first time a URL will be seen by our system and result in a “First Archive” event."
Glyn Moody reports on the Internet Archive's work in Open Access Faces Many Problems; Here's One That The Indispensable Internet Archive Is Helping To Solve:
"Although few people are aware of this project, it is vital work. There is little point publishing open access titles, theoretically available to all, if their holdings simply disappear at some point in the future. The Internet Archive's copies will ensure that doesn't happen. They are yet another indication of the invaluable and unique role the site plays in the online world."
Richard Heinberg is concerned with the future availability of energy. He writes in A simple way to understand what’s happening … and what to do:
"Forget 5G, the Internet of Things, and self-driving cars. Concentrate on low tech for the most part, and use renewable energy to supply electricity for applications that are especially important. During the last few decades we have digitized all human knowledge; if the grid goes down, we lose civilization altogether. We must choose what knowledge is essential and let the rest go, but that will take a while; in the interim, we need electricity to keep the grid up and running—and solar and wind can provide it."
Post a Comment