So, instead of re-architecting the way distros are built, vendors are reimplementing similar functionality using simpler tools inherited from the server world: containers, squashfs filesystems inside single files, and, for distros that have them, copy-on-write filesystems to provide rollback functionality.Proven goes on to discuss efforts along these lines at Red Hat, openSUSE, Canonical and EndlessOS.
The goal is to build operating systems as robust as mobile OSes: periodically, the vendor ships a thoroughly tested and integrated image which end users can't change and don't need to. In normal use, the root filesystem is mounted read-only, and there's no package manager.
If you don't blow your own horn, who will do it for you? So it falls to me to point out that this is a great, but rather tricky, idea that I have implemented versions of not once, but twice. The first time more than 30 years ago for SunOS 4.1 in prototype form at Sun Microsystems, and the second time nearly twenty years ago for OpenBSD in production for the LOCKSS Program at Stanford.
Below the fold is more detailed self-promotion.
SunOS 4.1
The prototype system was developed as part of an effort to re-engineer the Unix Vnode interface, which was at the time rapidly collecting cruft. It was published as Evolving the Vnode Interface at the Summer 1990 Usenix conference.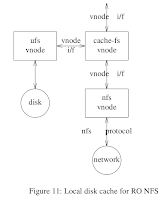 The paper describes a number of Vnode modules that can be stacked together to implement interesting functions. Among them was cache-fs, which layered a writable local file system above a local or remote read-only file system:
The paper describes a number of Vnode modules that can be stacked together to implement interesting functions. Among them was cache-fs, which layered a writable local file system above a local or remote read-only file system:This simple module can use any file system as a file-level cache for any other (read-only) file system. It has no knowledge of the file systems it is using; it sees them only via their opaque vnodes. Figure 11 shows it using a local writable ufs file system to cache a remote read-only NFS file system, thereby reducing the load on the server. Another possible configuration would be to use a local writable ufs file system to cache a CD-ROM, obscuring the speed penalty of CD.It could both improve the performance of the underlying file system and make it appear to be writable. I managed to get a prototype SunOS 4.1 running with the root file system composed of a tmpfs cache stacked above a CR-ROM, but I never managed to migrate it to having a persistent cache in ufs. Doing so tripped over locking issues to complex for a prototype.
The goal of this work was to re-configure Sun's operating system so that it could be distributed on a bootable CD-ROM. A major customer support problem at the time was identifying all local configurations and patches; the technicians on the customer support phones were essentially groping in the dark to figure out what code the broken system was actually running. With the OS file systems cached in a local ufs file system it would be easy, everything that was different from the vanilla distribution was in there. Diskless systems could be supported with a writable NFS stacked on a read-only NFS.
I wrote about the long history of stacking vnodes, including its pre-history and its post-history in the form of "union mounts", in 2015's It takes longer than it takes:
All I did was prototype the concept, and like many of my prototypes it served mainly to discover that the problem was harder than I initially thought. It took others another five years to deploy it in SunOS and BSD. Because they weren't hamstrung by legacy code and semantics by far the most elegant and sophisticated implementation was around the same time by Rob Pike and the Plan 9 team. Instead of being a bolt-on addition, union mounting was fundamental to the way Plan 9 worked.
OpenBSD
The production system was developed at the Stanford Library with significant help from Mark Seiden as the basis for the second generation of "LOCKSS boxes", and published as A Digital Preservation Network Appliance Based on OpenBSD at the 2003 BSDCon. The goal of the project was to enable libraries to collect and preserve for the long haul digital materials in the way they have materials on paper for centuries.Library budgets have been under pressure for decades, so the need was to minimize costs. With low-cost hardware and more importantly unskilled system administration, failure and compromise were to be expected:
The system evolved over about 3 years of testing to run at over 50 libraries worldwide and was generally sucessful in requiring neither great skill nor much attention from the host institution. This taught us many valuable lessons. The most important of these was that running the system exclusively from write-locked media (and from software verified against hashes on write-locked media) greatly simplifies two critical tasks: installing and configuring a new system, and recovering from a compromise.OpenBSD had locking issues similar to those of SunOS, and lacked union mounts, so running the system from a CD-ROM while retaining the ability to customize and upgrade it involved some contortions, detailed in the paper. In brief, we sacrified the read-only root. We ran with the root in a RAM file system and essentially all the O/S in a temporary file system. Both were writable, but during the boot sequence their entire contents were re-created with content whose hashes had been verified against information on read-only media.
In unskilled hands the process of installing and configuring a Unix system to be adequately secure is a daunting and error-prone task. Running an almost completely pre-configured system from write-locked media obviates almost all the effort and risk.
Restoring a compromised system is a daunting and error-prone task even in skilled hands. A simple reboot is all that is needed to restore the LOCKSS appliance to a known state.
Squashfs
The LOCKSS team were by no means the first. IoT systems have been using various means to run with read-only roots since the mid-90s. It is hard to use data compression on a writable file system; they usually require fixed-size blocks to allow files to be read fast and written. But read-only file systems can be compressed at creation time, with content de-compressed during each read operation.Many early efforts, for example the Linux Router Project (which squeezed a functional Linux system onto a boot floppy) used:
The compressed ROM/RAM file system (or cramfs) is a free (GPL'ed) read-only Linux file system designed for simplicity and space-efficiency. It is mainly used in embedded and small-footprint systems.It was useful but cramfs suffered from some major limitations, restricting file size and file system size, and lacked proper Linux file metadata. The file system Phillip Lougher wrote and released in 2002 to replace it, squashfs:
Unlike a compressed image of a conventional file system, a cramfs image can be used as it is, i.e. without first decompressing it. For this reason, some Linux distributions use cramfs for initrd images (Debian 3.1 in particular) and installation images (SUSE Linux in particular), where there are constraints on memory and image size.
Squashfs is a compressed read-only file system for Linux. Squashfs compresses files, inodes and directories, and supports block sizes from 4 KiB up to 1 MiB for greater compression. Several compression algorithms are supported.It supports the full set of Linux file metadata, and has become widely used in Linux Live CDs and in embedded systems. For example, the popular OpenWRT distribution for routers and wireless access points runs from a squashfs root file system with a JFFS2 file system mounted above it using overlayfs. This has many advantages, including the ability to customize the system with configurations and add-on packages in JFFS2, while retaining "failsafe" and "factory reset" capabilities in which the system is re-booted to run without the JFFS2 overlay and thus in a known-good state, similar to (but faster than) the result of a reboot of the LOCKSS OpenBSD system.
The ability rapidly to revert a system to a known-good state is a very important property, especially in today's hostile Internet environment.
Despite being a critical component of many products, squashfs suffers from the problem I discussed in Supporting Open Source Software. I believe, nearly 20 years later, Phillip Lougher is still supporting it on his own in his spare time.
4 comments:
> ...like many of my prototypes it served mainly to discover that the
> problem was harder than I initially thought.
Oh yes. Set this one to music. And on rare occasions, one escapes, and consumes lots of energy on its way to becoming more than a prototype.
Remind me: was the SunOS 4.1 project the same thing as "Pravda"?
I don't think it was Pravda but my memory isn't that great from 30 years ago.
Yawar Amin's The human toll of log4j maintenance nails the problem of unpaid open source maintenance:
"the log4j developers had this massive security issue dumped in their laps, with the expectation that they were supposed to fix it. How did that happen? How did a group of smart, hard-working people get roped into a thankless, high-pressure situation with absolutely no upside for themselves?"
Note that the paid engineers at Alibaba, who could have submitted a patch, simply notified the log4j developers that there was a problem and, 14 days later, told them "please hurry up". Entitled, no?
Open source means YOU can fix it.
Post a Comment