 |
| Source |
URLs shared on Twitter are automatically shortened to t.co links. Twitter does this to track its engagements and also protect its users from sites with malicious content. Twitter replaces these t.co URLs with HTML that suggests the original URL so that the end-user does not see the t.co URLs while browsing. When these t.co URLs are replayed through web archives, they are rewritten to an archived URL (URI-M) and should be rendered in the web archives as in the live web, without displaying these t.co URI-Ms to the end-user.But, as the screen-grab from the Wayback Machine shows, they may not be. Below the fold, a look at Jayanetti's explanation.
When an archived Web page is replayed, it is necessary to ensure that each link it contains does not refer to content on the live Web. If it does, the result is a "zombie", current content appearing where archived content should be. Preventing this involves rewriting the URLs in the links to point to the content in the archive. There are two ways to do this:
- Server-side rewriting, as used by the Wayback Machine.
- Client-side rewriting, which can be done in two ways:
- Using an HTTP proxy, as used by oldweb.today. The reader's browser requests the original URL, which in the oldweb.today case the proxy satisfies by requesting the unmodified content from multiple archives via Memento Aggregation.
- By the archive injecting Javascript into the otherwise unmodified page to be rendered, which intercepts URL requests and rewrites them to point into the archive.
We believe that the cause of this issue lies in the server-side rewriting rules for JSON files. The t.co URL in the tweet JSON is rewritten to an archived URL on the server-side. Twitter's JavaScript expects URLs to be 23 characters long "t.co" links and is therefore unable to remove the complete archived URL from the text during the replay.After running some experiments with specially crafted JSON, Jayanetti discovered a remarkable coincidence:
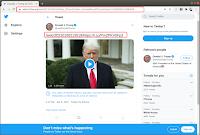
The URL gets rewritten at the server-side by Wayback Machine when the full-text value contains only a URL. However, note that only “/web/20200916204909/https://t.co/BS5JAFqReH” is displayed in the tweet with "https://web.archive.org" stripped off of the URI-M (Figure 4). ... The length of a t.co URL is 23 characters and is a fixed value that will rarely change. Therefore, Twitter's JavaScript is removing only the first 23 characters from the much longer t.co URI-M. It just happens that the string length of "https://www.archive.org" is also exactly 23 characters.The Wayback Machine has a problem. Consider this snippet of HTML:
<a href="https://www.example.com">https://www.example.com</a>The first https://www.example.com is a link and should be rewritten, the second is text and should not be rewritten. The HTML markup unambiguously distinguishes between the two cases. But here is the JSON used for one of Jayanetti's tests showing a simplified version of how URLs appear in Twitter's JSON:
{
"Case_1": "http://www.cs.odu.edu/",
"Case_2": "http://www.cs.odu.edu This is text",
"Case_3": "This is text https://www.cs.odu.edu/"
}
This is just 3 [key,value] pairs. The meaning of the keys, and thus whether the URLs should be rewritten, is ambiguous. It determined only by the Javascript that interprets the [key,value] pairs. The archive can't know this without actually rendering the page by executing the Javascript. Here is what the Wayback Machine did with Jayanetti's JSON:{
"Case_1": "https://web.archive.org/web/20210106172027/http://www.cs.odu.edu/",
"Case_2": "https://web.archive.org/web/20210106172027/http://www.cs.odu.edu This is text",
"Case_3": "This is text https://www.cs.odu.edu/"
}
There is no general way to decide whether to rewrite these URLs. Forced to guess, the Wayback Machine rewrites URLs that start the value, but not ones that appear later in the value. This is a reasonable policy for Twitter but, as Jayanetti discovered, error-prone. The result is:New UI tweets that share media (video, images) with no additional text have their t.co links rewritten on the server-side in the JSON. The resulting t.co URI-M is much longer than the usual 23 characters of a t.co URL. This results in Twitter's JavaScript stripping only "https://web.archive.org" (first 23 characters) from the complete URI-M but displaying the rest of the URI-M in the memento. However, Tweets with text and media do not have the t.co links rewritten, so their replay correctly duplicates their live Web behavior.As Jayanetti writes, these rendering flaws are "a minor impact that most people will disregard", but they demonstrate a problem for Web archives that will only get worse as sites "optimize the user experience" by delivering more of their content as JSON to be dynamically interpreted in the reader's browser.
No comments:
Post a Comment