I'm David Rosenthal from the LOCKSS (Lots Of Copies Keep Stuff Safe) Program at the Stanford University Libraries. For the last 15 years I've been working on the problem of keeping data safe for the long term. I'm going to run through some of the key lessons about storage we have learned in that time.
First, at scale this is an insoluble problem, in the sense that you are never going to know that you have solved it. Consider the simplest possible model of long-term storage, a black box into which you put a Petabyte and out of which 100 years later you take a Petabyte. You want to have a 50% chance that every bit you take out is the same as when it went in. Think of each bit like a radioactive atom that randomly decays. You have just specified a half-life for the bits; it is about 60M times the age of the universe. There's no feasible experiment you can do that would prove no process with a half-life less than 60M times the age of the universe was going on inside the box. Another way of looking at a Petabyte for a Century is that it needs 18 nines of reliability; 7 nines more reliable than S3's design goal.
We are going to lose stuff. How much stuff we lose depends on how much we spend storing it; the more we spend the safer the bits. Unfortunately, this is subject to the Law of Diminishing Returns. Each successive 9 of reliability is exponentially more expensive.

{kind=link}
Different technologies with different media service lives involve spending different amounts of money at different times during the life of the data. To make apples-to-apples comparisons we need to use the equivalent of Discounted Cash Flow to compute the endowment needed for the data. This is the capital sum which, deposited with the data and invested at prevailing interest rates, would be sufficient to cover all the expenditures needed to store the data for its life.
Until recently, this has not been a concern. Kryder's Law, the exponential increase in bit density on disk platters, meant the cost per byte of storage dropped about 40%/yr. If you could afford to store the data for a few years you could afford to store it "forever"; the cost rapidly became negligible.

In the past, with Kryder rates in to 30-40% range, we were in the flatter part of the graph where the precise Kryder rate wasn't that important in predicting the long-term cost. As Kryder rates decrease, we move into the steep part of the graph, which has two effects:
- The endowment needed increases sharply.
- The endowment needed becomes harder to predict, because it depends strongly on the precise Kryder rate.

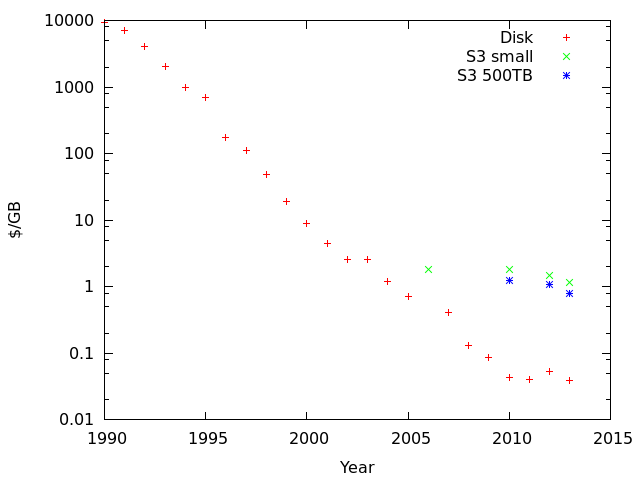
- Initially, S3 was somewhat more expensive than raw disk. Fair enough, it includes infrastructure, running costs and Amazon's margins.
- S3's Kryder rate is much lower than disk's, so over time it becomes a lot more expensive.

The justification for using the cloud is to save money. For peak-load usage, such as intermittent computations or temporary working storage, it certainly does. Amazon can aggregate a lot of spiky demands so they pay base-load costs and charge less than peak-load prices. Customers avoid the cost of over-provisioning to cope with the peaks.
For base-load computational and and in particular long-term storage tasks, below a certain scale the cloud probably does save money. The scale at which it stops saving money varies, but it is surprisingly low. The reason is two-fold:
- There are no spikes for Amazon to aggregate.
- To be cheaper than Amazon, your costs don't have to be cheaper than Amazon's, they only have to be cheaper than Amazon's costs plus Amazon's margins.
more than five times the compute capacity in use than the aggregate total of the other fourteen providersAmazon's margins on S3 may have been minimal at introduction, now they are extortionate, as Google has noticed:
cloud prices across the industry were falling by about 6 per cent each year, whereas hardware costs were falling by 20 per cent. And Google didn't think that was fair. ... "The price curve of virtual hardware should follow the price curve of real hardware."As the graph earlier showed, and as Glacier shows, Amazon introduces products at very competitive pricing, which it reduces much more slowly than its costs. As with books:
Amazon was simply following in the tradition of any large company that gains control of a market. “You lower your prices until the competition is out of the picture, and then you raise your prices and get your money back,” [Steven Blake Mettee] said.Google's recent dramatic price cuts suggest that they are determined to make the cloud a two-vendor market. But, as we see with the disk drive business itself, a two-vendor market is not a guarantee of low margins. Amazon cut prices in response to Google, but didn't go the whole way to match them. Won't they lose all their customers? No, bandwidth charges act to lock-in existing customers. Getting 1PB out of S3 into a competitor in 2 months costs about 2 months storage. If the competitor is 10% cheaper, the decision to switch doesn't start paying off for a year. Who knows if the competitor will still be 10% cheaper in a year? A competitor has to be a lot cheaper to motivate customers to switch.
Every few months there is another press release announcing that some new, quasi-immortal medium such as stone DVDs has solved the problem of long-term storage. But the problem stays resolutely unsolved. Why is this? Very long-lived media are inherently more expensive, and are a niche market, so they lack economies of scale. In 2009 Seagate did a study of the market for disks with an archival service life, which they could easily make, and discovered that no-one would pay the extra for them.
The fundamental problem is that long-lived media only make sense at very low Kryder rates. Even if the rate is only 10%/yr, after 10 years you could store the same data in 1/3 the space. Since space in the data center or even at Iron Mountain isn't free, this is a powerful incentive to move old media out. If you believe that Kryder rates will get back to 30%/yr, after a decade you could store 30 times as much data in the same space.
The reason that the idea of long-lived media is so attractive is that it suggests that you can design a system ignoring the possibility of media failures. You can't, because long-lived does not mean more reliable, it means that their reliability degrades more slowly with time. Even if you could it wouldn't make economic sense. As Brian Wilson, CTO of BackBlaze points out, in their long-term storage environment:
Double the reliability is only worth 1/10th of 1 percent cost increase. I posted this in a different forum: Replacing one drive takes about 15 minutes of work. If we have 30,000 drives and 2 percent fail, it takes 150 hours to replace those. In other words, one employee for one month of 8 hour days. Getting the failure rate down to 1 percent means you save 2 weeks of employee salary - maybe $5,000 total? The 30,000 drives costs you $4m.
The $5k/$4m means the Hitachis are worth 1/10th of 1 per cent higher cost to us. ACTUALLY we pay even more than that for them, but not more than a few dollars per drive (maybe 2 or 3 percent more).
Moral of the story: design for failure and buy the cheapest components you can. :-)

1 comment:
Rackspace is reluctant to engage in the price war, supporting my contention that the cloud services market will end up with two vendors.
Post a Comment