In particular, two projects at Stanford University and the University of California, Berkeley are most associated with the popularization of this concept. Stanford's MIPS would go on to be commercialized as the successful MIPS architecture, while Berkeley's RISC gave its name to the entire concept and was commercialized as the SPARC.For the last decade or more the debate has seemed frozen, with the CISC x86 architecture dominating the server and desktop markets, while the RISC ARM architecture dominated the mobile market. But two recent developments are shaking things up. Below the fold, some discussion.
 |
| Source |
Last month, Apple announced three products, Mac Mini, Mac Air, and 13" Macbook Pro based on their ARM-based M1 chip to ecstatic reviews:
the Mac mini (and its new MacBook Air and 13-inch MacBook Pro siblings) has Apple’s M1 system-on-a-chip, which includes an 8-core GPU, a CPU with four performance and four efficiency cores, a 16-core neural processing unit (NPU) called the Neural Engine, and a whole bunch of other stuff.All three replace products using Intel x86 chips, and the head-to-head comparisons showed the RISC completely outclassing the CISC in a market segment it had dominated for decades. Clearly this is a big deal.
Built on the ARM Instruction Set Architecture (ARM ISA), the M1 features 16 billion transistors and was manufactured in a 5nm process. According to Apple, each performance core in the M1 qualifies as the world’s fastest CPU core to date, while the efficiency cores match the performance of some recent Intel Macs.
Now, the are some obvious reasons why Intel is at a disadvantage in these comparisons. Apple's M1 is brand new, where the Intel chips are a couple of years old. And the M1 uses a 5nm process, where Intel has been struggling to upgrade its fabs:
Intel's press release also says that yields for its 7nm process are now twelve months behind the company's internal targets, meaning the company isn't currently on track to produce its 7nm process in an economically viable way. The company now says its 7nm CPUs will not debut on the market until late 2022 or early 2023.But the M1 also compares well to AMD's 7nm x86 CPUs so this isn't the whole explanation. Erik Engheim's Why is Apple’s M1 Chip So Fast? provides an excellent explanation for the lay audience. He starts from the basics (What is a Microprocessor (CPU)?) and goes on to explain that whereas Intel and AMD make CPUs that others build into systems such as PCs and servers, Apple makes systems that are implemented as a single chip, a System-on-Chip (SoC). Apple can do this where Intel and AMD can't because the SoC isn't their product, their product is a Mac that includes a SoC as a component.
One thing we understood when we started Nvidia more than a quarter of a century ago was that custom silicon to perform critical functions, such as 3D graphics, was an essential component of a PC. But the custom silicon had to be a separate chip. We used a state-of-the-art 500nm process. At 5nm Apple can put 10,000 times as many gates in the same chip area. So Apple can include the precise set of additional custom processors that match the needs to the product. In this case, not just 8 GPU cores, 16 Neural Engine cores, but also two different implementations of the ARM architecture, 4 optimized for speed and 4 optimized for efficiency to extend battery life.
Engheim explains the two main ways of making CPUs faster using the same process and the same clock rate, multiple cores and out-of-order execution, and their limitations. In the server space, having lots of cores makes a lot of sense; the demand is for many simultaneous tasks from many simultaneous users, and the alternative to adding cores to a CPU is to add CPUs to a server, which is more expensive.
But in the PC space there is only one user, and although the demand will be for several simultaneous threads, once that demand is satisfied extra cores provide no benefit. The M1's 8 cores are probably more than enough, which is indicated by Apple envisaging that, most of the time, the 4 low-power "efficiency" cores will do all the work. Note that, in adding cores, the only advantage RISC provides is that the simpler instruction set should make each core a bit smaller. Not a big deal.
But for compute-intensive tasks such as games, the other 4 cores need to be fast. Which is where out-of-order execution comes in, and RISC turns out to have a big advantage. Out-of-order execution means that instructions are fetched from memory, then decoded into "micro-operations", which can be thought of as instructions for the individual components of the core. The micro-operations are stored in a Re-Order Buffer (ROB), together with information about what data they need, and whether it is available. Instead of executing the micro-operations for each instruction, then executing the micro-operations for the next instruction, the core looks through the ROB finding micro-operations that have all the data they need and executing them. It does instructions as soon as it can, not waiting until the instruction before is complete.
Engheim explains the importance of the difference between the x86 ROB and the M1's:
It is because the ability to run fast depends on how quickly you can fill up the ROB with micro-ops and with how many. The more quickly you fill it up and the larger it is the more opportunities you are given to pick instructions you can execute in parallel and thus improve performance.RISC is the reason the M1 can have more decoders than x86. Engheim explains:
Machine code instructions are chopped into micro-ops by what we call an instruction decoder. If we have more decoders we can chop up more instructions in parallel and thus fill up the ROB faster.
And this is where we see the huge differences. The biggest, baddest Intel and AMD microprocessor cores have four decoders, which means they can decode four instructions in parallel spitting out micro-ops.
But Apple has a crazy eight decoders. Not only that but the ROB is something like three times larger. You can basically hold three times as many instructions. No other mainstream chipmaker has that many decoders in their CPUs.
You see, for x86 an instruction can be anywhere from 1–15 bytes long. On a RISC chip instructions are fixed size. Why is that relevant in this case?The result is that the M1's fast cores are effectively processing instructions twice as fast as Intel's and AMD's at the same clock frequency. And their efficiency cores are processing about as many using much less power.
Because splitting up a stream of bytes into instructions to feed into eight different decoders in parallel becomes trivial if every instruction has the same length.
However, on an x86 CPU, the decoders have no clue where the next instruction starts. It has to actually analyze each instruction in order to see how long it is.
The brute force way Intel and AMD deal with this is by simply attempting to decode instructions at every possible starting point. That means we have to deal with lots of wrong guesses and mistakes which has to be discarded. This creates such a convoluted and complicated decoder stage that it is really hard to add more decoders. But for Apple, it is trivial in comparison to keep adding more.
In fact, adding more causes so many other problems that four decoders according to AMD itself is basically an upper limit for how far they can go.
Using much less power for the same workload is one of the main reasons ARM dominates the mobile market, where battery life is crucial. That brings us to the second interesting recent RISC development. ARM isn't the only RISC architecture, it is just by a long way the most successful. Among the others with multiple practical implementations, RISC-V is I believe unique; it is the only fully open-source RISC architecture.
 |
| Source |
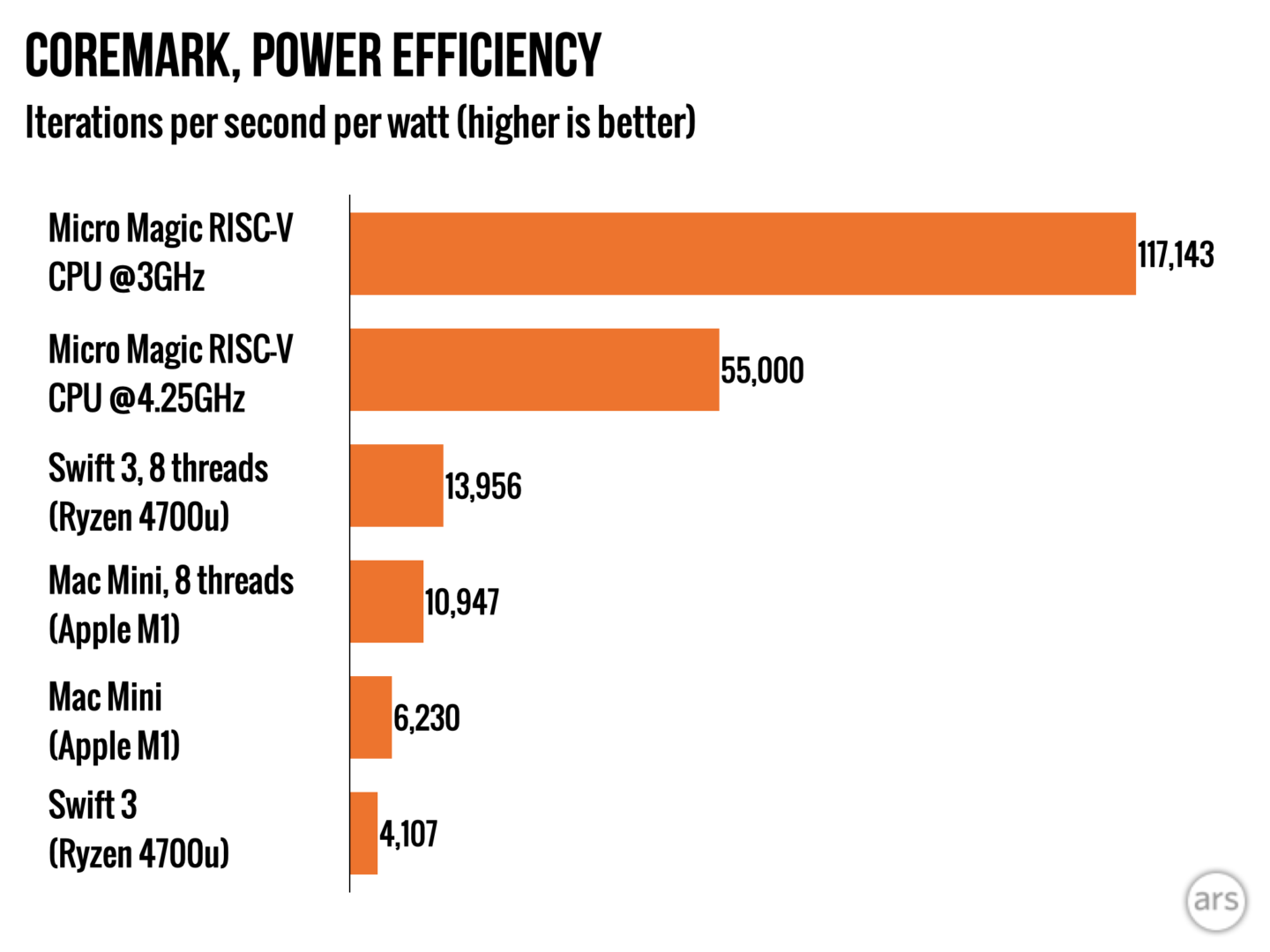
new prototype CPU, which appears to be the fastest RISC-V CPU in the world. Micro Magic adviser Andy Huang claimed the CPU could produce 13,000 CoreMarks (more on that later) at 5GHz and 1.1V while also putting out 11,000 CoreMarks at 4.25GHz—the latter all while consuming only 200mW. Huang demonstrated the CPU—running on an Odroid board—to EE Times at 4.327GHz/0.8V and 5.19GHz/1.1V.Some caveats are necessary:
Later the same week, Micro Magic announced the same CPU could produce over 8,000 CoreMarks at 3GHz while consuming only 69mW of power.
- The chip is a single-core prototype.
- The Micro Magic benchmarks are claimed, not independently verified.
- The Coremark benchmark is an industry standard for embedded systems, it isn't an appropriate benchmark for PC-type systems such as use the CPUs Salter is comparing it to.
- The power efficiency is impressive, but the raw single-core performance is merely interesting. At 5GHz it is about 1/3 the performance of one of the M1's four fast cores.
All of this sounds very exciting—Micro Magic's new prototype is delivering solid smartphone-grade performance at a fraction of the power budget, using an instruction set that Linux already runs natively on.P.S: more evidence of M1's impressive performance in Liam Tung's AWS engineer puts Windows 10 on Arm on Apple Mac M1 – and it thrashes Surface Pro X. The Surface Pro X uses an ARM chip co-developed by Qualcomm and Microsoft.
...
Micro Magic intends to offer its new RISC-V design to customers using an IP licensing model. The simplicity of the design—RISC-V requires roughly one-tenth the opcodes that modern ARM architecture does—further simplifies manufacturing concerns, since RISC-V CPU designs can be built in shuttle runs, sharing space on a wafer with other designs.
...
Still, this is an exciting development. Not only does the new design appear to perform well while massively breaking efficiency records, it's doing so with a far more ideologically open design than its competitors. The RISC-V ISA—unlike x86, ARM, and even MIPS—is open and provided under royalty-free licenses.
3 comments:
See also Chris Mellor's Seagate says it's designed two of its own RISC-V CPU cores – and they'll do more than just control storage drives:
"Seagate says it has, after several years of effort, designed two custom RISC-V processor cores for what seems a range of functions including computational storage.
The disk drive maker told us one of the homegrown CPUs is focused on high performance, and the other is optimized for area, ie: it's less powerful though smaller and thus uses takes up less silicon on a die. Both cores are said to include RISC-V's security features, and are drive-agnostic, which means that they can be used with SSDs as well as hard disk drives."
A minor nit, though I agree with all the architectural and design commentary around the RICS vs CISC debate!
The nanometer process used these days is a squirrelly a comparison on an actual performance and process basis. Said better than I can phrase: "Having looked at the above comparison, and highlighted it in his video, der8auer challenges the obvious conclusion that Intel 14nm+++ and TSMC 7nm are very similar in physical scale, reminding viewers that the above pictures don't fully represent the 3D structure that is so important to modern chip optimisation. Moreover, the relationship between node size, half-pitch, and gate length has significantly loosened since the early 1990s. The XXnm figure reflects process history more than progress, asserts the OC expert, and thus it isn't very useful as a metric to compare between chip makers.
Another metric, probably worth closer consideration is transistor density, as revealed by the chip fabricators. Intel 10 nm and TSMC 7nm processes both produce dies with approx 90 million transistors per sq millimetre"
https://hexus.net/tech/news/cpu/145645-intel-14nm-amdtsmc-7nm-transistors-micro-compared/
*(Full disclosure, I do work for Intel Labs, though I'm about a million miles away from anything touching CPUs, still doing storage systems software work these days :) )
Simon Sharwood reports from Amazon's re:invent conference:
"DeSantis said the reason that commercial UPSes and switch gears don’t meet its needs is that they’re designed for the many scenarios in which they’ll be put to work, rather than Amazon’s requirements. The same logic goes into developing CPUs, he said, arguing that the likes of Intel and AMD design products that will sell well by making them general-purpose devices.
The result is processors that pack in features to make them suitable for more tasks. When raw power was needed, multi-core CPUs were the answer. When utilisation rates of CPUS became an issue, simultaneous multithreading came along. None of that tech ever left mainstream CPUs, DeSantis argued, and the result is architectures ripe for side-channel attacks and which delivers variable performance (which is why the HPC crowd turn off SMT)."
The result is their ARM-based Graviton CPUs:
"AWS would rather processors designed for the cloud. Hence its investment in Graviton, the many-core architecture and extra-large caches as they allow better per-core performance without the need for other trickery. The architecture is designed from the ground up for microservices, which AWS sees as the dominant wave of software development.
“Graviton 2 delivers 2.5-3 times better performance/watt than any other CPU in our cloud,” DeSantis said."
Post a Comment