I gave a talk at CNI's Fall 2012 Membership Meeting entitled The Truth Is Out There: Preservation and the Cloud. It was an updated and shortened version of a seminar I had given in mid-November at UC Berkeley's School of Information. Below the fold is an edited text with links to the resources.
Tuesday, December 11, 2012
Monday, December 10, 2012
Sharing makes Glacier economics even better
A more detailed analysis of the economics of Glacier sharing the same infrastructure as S3 than I posted here makes the picture look even better from Amazon's point of view. The point I missed is
that the infrastructure is shared. Follow me below the fold for the details.
Friday, December 7, 2012
Nostalgia
Google has a nice post with a short video commemorating today's 50th birthday of the Ferranti Atlas, the UK's first "supercomputer". Although it wasn't the first computer I programmed, Cambridge University's Atlas 2 prototype, called Titan, was the machine I really learned programming on, starting in 1968. It was in production from 1966 to 1973 with a time-sharing operating system using Teletype KSR33 terminals, a device-independent file system and many other ground-breaking features. I got access to it late at night as an undergraduate member of the Archimedeans, the University Mathematical Society. I wrote programs in machine code (as I recall there was no mnemonic assembler, you had to remember the numeric op-codes), in Atlas Autocode, and in BCPL. Best of all, it was attached to a PDP-7 with a DEC 340 display, which a friend and I programmed to play games.
Thursday, December 6, 2012
Updating "More on Glacier Pricing"
In September I posted More on Glacier Pricing including a comparison with our baseline local storage model. Last week I posted Updating "Cloud vs. Local Storage Costs which among other things updated and corrected the baseline local storage model. Thus I needed to updated the comparison with Glacier too. Below the fold is this updated comparison, together with a back-of-the-envelope calculation to support the claim I've been making that although Glacier may look like tape, it could just be using S3's disk storage infrastructure.
Friday, November 30, 2012
Updating "Cloud vs. Local Storage Costs"
A number of things have changed since I wrote my "Cloud vs. Local Storage Costs" post in June that impact the results:
- Amazon reduced S3 prices somewhat. As of December 1st, in response to a cut by Google, there will be a further cut.
- Disk prices have continued their slow recovery from the Thai floods.
- 4TB SATA drives are in stores now, albeit at high prices.
- Michael Factor pointed out that I hadn't correctly accounted for RAID overhead in my original calculation.
Thursday, November 15, 2012
Bandwidth costs for Cloud Storage
Our analysis of the costs of cloud storage assumes that the only charges for bandwidth are those levied by the cloud storage service itself. Typically services charge only for data out of the cloud. From our privileged viewpoint at major universities, this is a natural assumption to make.
At The Register Trevor Potts looks at the costs of backing up data to the cloud from a more realistic viewpoint. He computes the cost and time involved for customers who have to buy their Internet bandwidth on the open market. He concludes that for small users cloud backup makes sense:
At The Register Trevor Potts looks at the costs of backing up data to the cloud from a more realistic viewpoint. He computes the cost and time involved for customers who have to buy their Internet bandwidth on the open market. He concludes that for small users cloud backup makes sense:
I can state with confidence that if you have already have a business ADSL with 2.5Mbps upstream and at least a 200GB per month transfer limit (not hard to find in urban areas in most developed nations) then cloud storage for anything below 100GB per month will make sense. The convenience and reliability are easily worth the marginal cost.For his example large user at 15TB/mo with a 100Mbit fiber connection, the bandwidth costs from the ISP are double the storage charges from Amazon, for a total of $4374. And recovery from the backups would cost about as much as a month's backup, and would take a month to boot. That simply isn't viable when compared to his local solution:
The 4TB 7200 RPM Hitachi Deskstar sells for $329 at my local computer retailer. Five of these drives (for RAID 5) is $1,645; a Synology DS1512+ costs $899. A 10x10 storage unit is $233/month, and the delivery guy costs me $33 per run. So for me to back up 15TB off-site each month is $2,800 per month.Of course, in many cases libraries and archives are part of large institutions and their bandwidth charges are buried in overhead. And the bandwidth usage of preservation isn't comparable to backup; the rate at which data is written is limited by the rate at which the archive can ingest content. On the whole, I believe it is reasonable for our models to ignore ISP charges, but Trevor's article is a reminder that this isn't a no-brainer.
Monday, November 12, 2012
BIts per square inch vs. Dollars per GB
A valid criticism of my blog posts on the economics of long-term storage, and of our UNESCO paper (PDF), is that we conflate Kryder's Law, which describes the increase in the areal density of bits on disk platters, with the cost of disk storage in $/GB. We waved our hands and said that it roughly mapped one-for-one into a decrease in the cost of disk drives. We are not alone in using this approximation, Mark Kryder himself does (PDF):
Density is viewed as the most important factor ... because it relates directly to cost/GB and in the HDD marketplace, cost/GB has always been substantially more important than other performance parameters. To compare cost/GB, the approach used here was to assume that, to first order, cost/GB would scale in proportion to (density)-1My co-author Daniel Rosenthal has investigated the relationship between bits/in2 and $/GB over the last couple of decades. Over that time, it appears that about 3/4 of the decrease in $/GB can be attributed to the increase in bits/in2. Where did the rest of the decrease come from? I can think of three possible causes:
- Economies of scale. For most of the last two decades the unit shipments of drives have been increasing, resulting in lower fixed costs per drive. Unfortunately, unit shipments are currently declining, so this effect has gone into reverse.
- Manufacturing technology. The technology to build drives has improved greatly over the last couple of decades, resulting in lower variable costs per drive. Unfortunately HAMR, the next generation of disk drive technology has proven to be extraordinarily hard to manufacture, so this effect has gone into reverse.
- Vendor margins. Over the last couple of decades disk drive manufacturing was a very competitive business, with numerous competing vendors. This gradually drove margins down and caused the industry to consolidate. Before the Thai floods, there were only two major manufacturers left, with margins in the low single digits. Unfortunately, the lack of competition and the floods have led to a major increase in margins, so this effect has gone into reverse.
Thursday, November 8, 2012
Format Obsolescence In The WIld?
The Register has a report that, at a glance, looks like one of the long-sought instances of format obsolescence in the wild:
Andrew Brown asked to see the echocardiogram of his ticker, which was taken eight years ago. He was told that although the scan is still on file in the Worcestershire Royal hospital, it will cost a couple of grand to recreate the data as an image because it is stored in a format that can no longer be read by the hospital's computers.But looked at more closely below the fold we see that it isn't so simple.
Tuesday, October 30, 2012
Forcing Frequent Failures
My co-author Mema Roussopoulos pointed me to an Extremetech report on Harvard team's success in storing 70 billion copies of a 700KB file in about 60 grams of DNA:
However DNA, like all "archival" media, poses a system-level problem. Below the fold I discuss the details.
Scientists have been eyeing up DNA as a potential storage medium for a long time, for three very good reasons: It’s incredibly dense (you can store one bit per base, and a base is only a few atoms large); it’s volumetric (beaker) rather than planar (hard disk); and it’s incredibly stable — where other bleeding-edge storage mediums need to be kept in sub-zero vacuums, DNA can survive for hundreds of thousands of years in a box in your garage.I believe that DNA is a better long-term medium than, for example, the "stone" DVDs announced last year. The reason is that "lots of copies keep stuff safe", and with DNA it is easy to make lots of copies. The Harvard team made about 70 billion copies, which is a lot by anyone's standards. Their paper in Science is here.
However DNA, like all "archival" media, poses a system-level problem. Below the fold I discuss the details.
Tuesday, October 23, 2012
Peak Disk?
Thomas Coughlin has a blog post up at Forbes entitled "Have Hard Disk Drives Peaked?". It continues the optimism I poked fun at in Dr Pangloss' Notes From Dinner, concluding:
Coughlin is talking about unit shipments, and he estimates:
Have hard disk drives peaked? We don’t think the evidence supports this yet. There is just too much digital content to be stored and more HDDs may be required than in prior years to keep this growing content library. While the market for regular computers has certainly been impacted by smartphones, tablets and other thin clients that are served by massive data centers through the cloud there is still a market for faster personal computers using flash memory (especially in combination with HDDs). Thus we don’t think that HDDs have peaked but instead that they could experience significant annual growth in a stronger economy.It sparked a spirited discussion on a storage experts mail list but, as with the dinner Dr. Pangloss attended, the underlying assumption was that the demand for storage is inelastic; people will just pay whatever it takes to buy the 60% more storage for this year's bytes as compared to last year's.
Coughlin is talking about unit shipments, and he estimates:
overall shipments of HDDs in 2012 will be about 592 M (down about 5.2% from 2011). This estimate for 2012, combined with the drop in 2011 means that HDDs have experienced two consecutive years of shipment decline,Summarizing the discussion, there appear to be six segments of the hard disk business, of which four are definitely in decline:
- Enterprise drives: Flash is killing off the systems that enterprises used to use for performance-critical data. These were based around buying a lot of very fast, relatively small capacity and expensive disks and using only a small proportion of the tracks on them. This reduced the time spent waiting for the head to arrive at the right track, and thus kept performance high albeit at an extortionate cost. Flash is faster and cheaper.
- Desktop drives: Laptops and tablets are killing off desktop systems, so the market for the 3.5" consumer drives that went into them is going away.
- Consumer embedded: Flash and the shift of video recorder functions to the network have killed this market for hard disks.
- Mobile: Flash has killed this market for hard disks.
- Enterprise SATA: Public and private cloud storage systems are growing and hungry for the highest GB per $ drives available, but the spread of deduplication and the arrival of 4TB drives will likely slow the growth of unit shipments somewhat.
- Branded drives: This market is mostly high-capacity external drives and SOHO NAS boxes. Cloud storage constrains its growth, but the bandwidth gap means that it has a viable niche.
"There are several dynamics currently limiting market demand: first, global macroeconomic weakness, which is impacting overall IT spending; second, product transitions in the PC industry; and third, the continued adoption of tablets and smartphones, which is muting PC sales growth."But they too believe that demand for storage is inelastic:
because customers have to "store, manage and connect the massive and growing amounts of digital data in their personal and professional lives. This opportunity extends well into the future".No doubt Dr. Pangloss would agree.
Saturday, October 13, 2012
Cleaning up the "Formats through tIme" mess
As I said in this comment on my post Formats through time, time pressure meant that I made enough of a mess of it to need a whole new post to clean up. Below the fold is my attempt to remedy the situation.
Thursday, October 11, 2012
DId The Good Guys Just Win One?
I have been saying for years that the big problem with digital preservation is economic, in that no-one has enough money to do a good job of preserving the stuff that needs to be preserved. Another way of saying the same thing is that our current approaches to digital preservation are too expensive. One major reason why they're too expensive is that almost everything is copyright. Thus, unless you are a national library, you either have to follow the Internet Archive's model and depend on the "safe harbor" provision of the DMCA, making your collection hostage to bogus take-down notices, or you have to follow the LOCKSS and Portico models and obtain specific permission from the copyright holder, which is expensive.
Reading this excellent post by Nancy Sims, it seems as though Judge Baer, in ruling on motions for summary judgement in the case of Author's Guild v. Hathi Trust may have changed that dilemma. Nancy writes:
Reading this excellent post by Nancy Sims, it seems as though Judge Baer, in ruling on motions for summary judgement in the case of Author's Guild v. Hathi Trust may have changed that dilemma. Nancy writes:
Although the judge did say that preservation copying, on its own, may not be transformative, he also said that preservation copying for noncommercial purposes is likely to be fair use.If this ruling holds up, it will have a huge effect on how we go about preserving stuff and how expensive it is. If preservation copying for noncommercial use is fair use, the need to get for libraries and archives to get specific permission to make copies for preservation goes away. There is a great deal of other good stuff in Nancy's post, go read it.
Tuesday, October 9, 2012
Formats through time
Two interesting and important recent studies provide support for the case I've been making for at least the last 5 years that Jeff Rothenberg's pre-Web analysis of format obsolescence is itself obsolete. Details below the fold.
Monday, October 1, 2012
Storage Will Be A Lot Less Free Than It Used To Be
I presented our paper The Economics of Long-Term Digital Storage (PDF) at UNESCO's "Memory of the World in the Digital Age" Conference in Vancouver, BC. It pulls together the modeling work we did up to mid-summer. The theme of the talk was, in a line that came to me as I was answering a question, "storage will be a lot less free than it used to be". Below the fold is an edited text of my talk with links to the sources.
Thursday, September 27, 2012
Notes from Desiging Storage Architectures workshop
Below the fold are some notes from this year's Library of Congress Designing Storage Architectures meeting.
Friday, September 21, 2012
Talk at "Designing Storage Architectures"
I gave a talk at the Library of Congress' Designing Storage Architecture workshop entitled The Truth Is Out There: Long-Term Economics in the Cloud. Below the fold is an edited text with links to the resources.
Wednesday, September 19, 2012
Two New Papers
A preprint of our paper The Economics of Long-Term Digital Storage (PDF) is now on-line. It was accepted for the UNESCO conference The Memory of the World in the Digital age: Digitization and Preservation in Vancouver, BC, and I am scheduled to present it on the morning of September 27 (PDF). The paper pulls together the work we had done on economic models up to the submission deadline earlier this summer, and the evidence that Kryder's Law is slowing.
LOCKSS Boxes in the Cloud (PDF) is also on-line. It is the final report of the project we have been working on for the Library of Congress' NDIIPP program to investigate the use of cloud storage for LOCKSS boxes.
LOCKSS Boxes in the Cloud (PDF) is also on-line. It is the final report of the project we have been working on for the Library of Congress' NDIIPP program to investigate the use of cloud storage for LOCKSS boxes.
Friday, September 14, 2012
Correction, please! Thank you!
I'm a critic of the way research communication works much of the time, so it is nice to draw attention to an instance where it worked well.
The UK's JISC recently announced the availability of the final version of a report the Digital Curation Centre put together for a workshop last March. "Digital Curation and the Cloud" cited my work on cloud storage costs thus:
The UK's JISC recently announced the availability of the final version of a report the Digital Curation Centre put together for a workshop last March. "Digital Curation and the Cloud" cited my work on cloud storage costs thus:
David Rosenthal has presented a case to suggest that cost savings associated with the cloud are likely to be negligible, although local costs extend far beyond those associated just with procuring storage media and hardware.Apparently this was not the authors' intention, but the clear implication is that my model ignores all costs for local storage except those "associated just with procuring storage media and hardware". Clearly, there are many other costs involved in storing data locally. But in the cited blog post I say, describing the simulations leading to my conclusion:
A real LOCKSS box has both capital and running costs, whereas a virtual LOCKSS box in the cloud has only running costs. For an apples-to-apples comparison, I need to compare cash flows through time.Further, I didn't "suggest that cost savings associated with the cloud are likely to be negligible". In the cited blog post I showed that for digital preservation, not merely were there no "cost savings" from cloud storage but rather:
Unless things change, cloud storage is simply too expensive for long-term use.Over last weekend I wrote to the primary author asking for a correction. Here it is Friday and the report now reads:
David Rosenthal has presented a case to suggest that cloud storage is currently "too expensive for long term use" in comparison with the capital and running costs associated with local storage.Kudos to all involved for the swift and satisfactory resolution of this issue. But, looking back at my various blog posts, I haven't been as clear as I should have been in describing the ways in which my model of local storage costs leans over backwards to be fair to cloud storage. Follow me below the fold for the details.
Tuesday, September 11, 2012
More on Glacier Pricing
I used our prototype long-term economic model to investigate Amazon's recently announced Glacier archival storage service. The results are less dramatic than the hype. In practice, unlike S3, it appears that it can have long-term costs roughly the same as local storage, subject to some caveats. Follow me below the fold for the details.
Tuesday, September 4, 2012
Threat Models For Archives
I spent some time this week looking at a proposed technical architecture for a digital archive. It seems always to be the case that these proposals lack any model of the threats against which the data has to be protected. This one was no exception.
It is a mystery how people can set out to design a system without specifying what the system is supposed to do. In 2005 a panel of the National Science Board reported on the efforts of the US National Archives and Records Administration to design an Electronic Records Archive (ERA):
From 4 years ago, here is an example of the threats paper archives must guard against. The historian Martin Allen published a book making sensational allegations about the Duke of Windsor's support for the Nazis. It was based on "previously unseen documents" from the British National Archives, but:
It is a mystery how people can set out to design a system without specifying what the system is supposed to do. In 2005 a panel of the National Science Board reported on the efforts of the US National Archives and Records Administration to design an Electronic Records Archive (ERA):
"It is essential that ERA design proposals be analyzed against a threat model in order to gain an understanding of the degree to which alternative designs are vulnerable to attack."That same year the LOCKSS team published the threat model the LOCKSS design uses. Despite these examples from 7 years ago, it seems that everyone thinks that the threats to stored data are so well understood and agreed upon that there is no need to specify them, they can simply be assumed.
From 4 years ago, here is an example of the threats paper archives must guard against. The historian Martin Allen published a book making sensational allegations about the Duke of Windsor's support for the Nazis. It was based on "previously unseen documents" from the British National Archives, but:
"... an investigation by the National Archives into how forged documents came to be planted in their files ... uncovered the full extent of deception. Officials discovered 29 faked documents, planted in 12 separate files at some point between 2000 and 2005, which were used to underpin Allen's allegations."Is this a threat your digital preservation system could prevent or even detect? Could your system detect it if the perpetrator had administrative privileges? The proposed system I was looking at would definitely have failed the second test, because insider abuse was not part of their assumed threat model. If the designers had taken the time to write down their threat model, perhaps using our paper as a template, they would have either caught their omission, or explained how it came to be that their system administrators were guaranteed to be both infallible and incorruptible.
Tuesday, August 28, 2012
Re-thinking Storage Technology Replacement Policy
We are now at work on the replacement for our two initial economic models, combining the detailed view of the short-term model with the big picture of the long-term model. As I explained in an earlier post, the policy that determines when storage media are replaced by successors has interesting effects on the outcome. Now I have to implement this policy for the new model, and I'm finding that the additional level of detail from the short-term model makes this a lot more complex. Below the fold is a wonkish discussion of these complexities.
Tuesday, August 21, 2012
Amazon's Announcement of Glacier
Today's announcement from Amazon of Glacier vindicates the point I made here, that the pricing model of cloud storage services such as S3 is unsuitable for long-term storage. In order to have a competitive product in the the long-term storage market Amazon had to develop a new one, with a different pricing model. S3 wasn't competitive. Details are below the fold.
Tuesday, July 31, 2012
Three Numbers Presage A Crisis
Bill McKibben's Rolling Stone article "Global Warming's Terrifying New Math" is essential reading. The sub-head describes it:
Three simple numbers that add up to global catastrophe - and that make clear who the real enemy is.Inspired by Bill, here are three numbers I've cited before that indicate we're heading for a crisis in digital storage:
- According to IDC, the demand for storage is growing about 60%/year.
- According to IHS iSuppli, the bit density on the platters of disk drives will grow about 20%/yr for the next 5 years. In the past, increases in bit density have led to corresponding drops in $/GB.
- According to computereconomics.com, IT budgets in recent years have grown between 0%/year and 2%/year.
{kind=link}
Tuesday, July 24, 2012
Storage Technology Replacement Policy

The region between Kryder rates of 25% and 35% is flat. It seems strange that, with storage prices dropping faster, the endowment needed isn't dropping too. I finally got time to figure out what is going on, and I now believe this is an artefact of the technology replacement policy model I implemented as part of the prototype model. It isn't that the policy model is unrealistic, although there is plenty of room for disagreement about alternative policies. Rather, the parameters I gave the policy model to generate this graph were unrealistic. Follow me below the fold for what Paul Krugman would call a wonkish explanation.
Thursday, July 19, 2012
Governments Rewriting History
Every so often I like to point to stories showing the importance, especially for government documents, of having multiple copies under independent, preferably somewhat antagonistic, administration as happened with the Federal Depository Library Program for paper, and as happens in the USDocs Private LOCKSS Network for digital documents. The reason is that governments are especially incapable of resisting the temptation, common to everyone, to edit history to make it less embarrassing. The great George Orwell understood this; Winston Smith's job in 1984 was rewriting history to make it conform to current ideology.
My latest example comes via Yves Smith's excellent blog, naked capitalism. She points to an article at Alternet by Thomas Ferguson, Paul Jorgenson and Jie Chen which describes how records of some major contributions to the 2007-8 election cycle have mysteriously vanished from the Federal Election Commission's database of political contributions.
In 2008, however, a substantial number of contributions to such 501(c)s made it into the FEC database. For the agency quietly to remove them almost four years later with no public comment is scandalous. It flouts the agency’s legal mandate to track political money and mocks the whole spirit of what the FEC was set up to do. No less seriously, as legal challenges and public criticism of similar contributions in the 2012 election cycle rise to fever pitch, the FEC’s action wipes out one of the few sources of real evidence about how dark money works. Obviously, the unheralded purge also raises unsettling questions about what else might be going on with the database that scholars and journalists of every persuasion have always relied upon.They write:
While you knew FEC data was unlikely to be the last word, you could be confident that whatever the agency did report was as true as it could make it. That the FEC would ever delete true reports of politically relevant money was literally unthinkable.Other sources had made copies of the FEC data and added value:
Comprehending their formatting and correctly interpreting their myriad rows and columns required the patience of Job and the informal equivalent of a BS in computer science. As a consequence, most researchers threw up their hands. They didn’t directly use FEC data; instead they relied upon data reworked by some for-profit reseller, or more commonly, the Center for Responsive Politics.The journalists were re-examining the FEC's database:
For the 2007-'08 election cycle, for example, we found millions of dollars in political contributions that appear to have escaped earlier nets. We are also able to do a much better job of aggregating contributions by large donors, which is key to understanding how the system really works.What they found was:
We discovered the FEC deletions when cross-checking our results for big-ticket contributors. These deletions do not at all resemble other post-election corrections that the FEC routinely makes to its data downloads.They then give a series of examples of large donors whose contributions to the 2007-8 cycle have been whitewashed away.
The interesting and different thing about this public "naming and shaming" is that it had an effect. The very next day, the Alternet reporters found that at least some of the missing data had mysteriously re-appeared:
In mid-morning, certain reporters began tweeting that it was easy to find contributions that we specifically discussed on the FEC website. We checked one particularly famous name that we had also looked up only a few days before and found that he was indeed back.The Tweeters who doubted the Alternet story were easily refuted because:
These downloads are public and dated, so anyone can verify what’s in them. The 2008 contribution by Harold Simmons that we mentioned is in the January download. It is not in the July 8 download. The same is true for other contributions we discussed to Let Freedom Ring by John Templesman, Jr., and Foster Friess. More broadly, the entire set of “C9” files covering 501(c)4 that we discussed is gone from the July download, with the trivial exception we mentioned. Needless to say, we checked the FEC’s database many times ourselves and we indicated that the original record of contributions by Simmons (and others) could still be found, if you knew exactly where to look.The whole story, which was made possible by archiving copies of what the government was publishing when it was being published, seems to be having a happy ending. Except, perhaps, for the FEC. The credibility of the information they publish has been degraded, and will stay degraded until they come up with an explanation of what exactly happened and how they plan to make sure it never happens again. The FEC should look to Amazon for an example of how to make this kind of information public.
Tuesday, July 17, 2012
Storage roundup July 2012
From my continuing series on the dismal outlook for Kryder's Law, The Register reports on the continuing impact of the Thai floods:
Hard disk drive prices are unlikely to return to pre-flood levels until 2014 despite rising production levels, thanks to surging demand, vendor lock-in and a market dominated by just two suppliers, according to analysts.Had there been no floods, and had the industry managed even just the 20%/yr increase in bit density that is now projected, and had margins remained stable instead of increasing dramatically, prices in 2014 would have been about 1/2 their pre-flood levels. So, three years later, costs will be at least double what would have been predicted before the floods.
More recent reports suggest that Western Digital is recovering somewhat better than was expected:
Keene said WD had "recovered" more quickly than industry commentators had forecast – the plants were nearing full capacity some months ago – and said only some high-spec products remained in tight supply.while Seagate is having greater difficulty:
Seagate will miss its fourth quarter's sales target as its competitors recover faster than expected from floods that knackered hard drive supplies.As part of a feature series on the solid state storage revolution, Ars Technica has a useful overview of the future of SSDs., with a clear explanation of why shrinking the flash cell size reduces not just the data retention time but also the number of write cycles a cell can sustain, and why moving from MLC (2 bits per cell) to TLC (3 bits per cell) makes the problems even worse. The article describes the contortions flash controller makers are going through to mitigate these problems, which are starting to sound like those the hard disk makers are struggling with. The article is suitably sceptical about the prospects for alternative solid state memories, but moderately enthusiastic about memristors. This is good news because:
a significant number of folks who have suffered through SSD failure have so suffered not because the flash wore out, but rather because of an actual component failure—a flash chip died, say, or the controller died. Component failure can occur in any device, and if memristor-based drives are eventually manufactured and assembled in the same plants by the same companies who make today's HDDs and SSDs—and we have every reason to believe they will be—then a memristor-based storage drive with a million-write endurance rating would likely be effectively immortal. Other components are likely to fail long before the storage medium reaches its write endurance limit.The Register hits some of the same points and teases out some of the business implications:
There are several post-NAND technologies jostling for prominence, such as Phase-change memory, resistive RAM, memristors and IBM's Racetrack memory. All promise greater capacity, higher speed and longer endurance than flash. It's not clear which one of them will become the non-volatile memory follow-on from NAND, but, whichever it is, the controller software crafter to cope with NAND inadequacies won't be needed.
MLC NAND wear-levelling and write amplification reduction technology won't be needed. The NAND signal processing may be irrelevant. Garbage collection could be completely different. Entire code stacks will need to be re-written. All the flash array and hybrid flash/disk startups will find their software IP devalued and their business models at risk from post-NAND startup's IP with products offering longer life and faster-performance.One solid state storage technology wasn't included in these reviews because it was only announced July 10. Karlsruhe Institute of Technology managed to build a memristor-like 1-bit device using only 51 atoms:
They point out that a bit on a hard disk drive uses about 3 million atoms while their molecule has just 51 atoms inside it, including the single iron atom they've inserted at its centre. Wow, that's 58,823.5 times denser, say 50,000X for argument's sake, which would mean a 4TB hard drive could store 200PB using molecular bit storage. - except that it couldn't ... If molecular bit storage is ever going to be used, it will be in solid state storage and you will still need to access the bits – with one wire to deliver the electric pulse to set them and another wire to sense their setting. Even using nanowires, more space in the device would be taken up by circuitry than by storage.At Slashdot, Lucas123 describes how hybrid drives, the compromise between SSDs and hard disks, which add a small amount of solid state storage to a normal hard drive, do not in fact deliver the advantages of both with the disadvantages of neither and so are not succeeding in the market:
New numbers show hybrid drives, which combine NAND flash with spinning disk, will double in sales from 1 million to 2 million units this year. Unfortunately for Seagate — the only manufacturer of hybrids — solid-state drive sales are expected to hit 18 million units this year and 69 million by 2016. ... If hybrid drives are to have a chance at surviving, more manufacturers will need to produce them, and they'll need to come in thinner form factors to fit today's ultrabook laptops.The Register reports on a briefing on disk technology futures from Western Digital, which repeated Dave Anderson of Seagate's (PDF) 2009 point that there is no feasible alternative to disks in the medium term:
The demand for HDD capacity continues unabated as there is no alternative whatsoever for fast access to online data; NAND flash fabs are in short supply and have a long lead time. In 2011, 70 per cent of all the shipped petabytes were HDDs, with optical, tape, NAND and DRAM making up the rest. Some 350,000PB of disk were shipped, compared to about 20,000 PB of NAND.Here is WD's version of the Kryder's Law curve, on a scale that minimises the slowing from 40%/yr to 20%/yr in the last few years, and they play that down as temporary in words too:
WD's COO, Tim Leyden, reckons another 40 NAND fabs would be needed to make 350K PB of NAND, and that would cost $400bn at $10bn/fab capable of shipping 8.8K PB/year. It isn't going to happen any time soon.
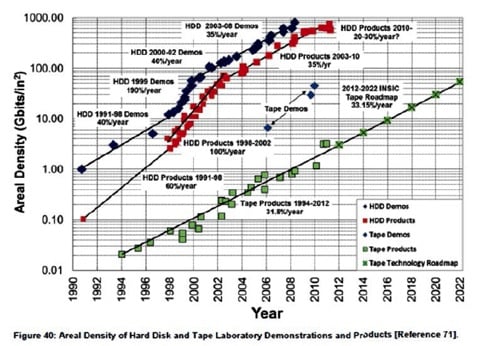
WD says that HDD areal density growth has slowed from an annual 40 per cent compound annual growth rate to just 20 per cent as the current PMR recording technology nears its maximum efficacy, with a transition to energy-assisted magnetic recording (EAMR) coming and representing the possibility of regaining the 40 per cent rate.But they are clearly concerned enough to raise the possibility of adding platters (and thus cost):
Our contact said that 5-platter 3.5-inch drives were a possibility.
With a trend towards thin and light drives for Ultrabooks, the possibility of platter addition is denied in this market sector.

Vendors shipped close to 489 million smartphones in 2011, compared to 415 million PCs. Smartphone shipments increased by 63% over the previous year, compared to 15% growth in PC shipments.Finally, on June 29th at the height of the "derecho" storm affecting the DC area, Amazon's cloud suffered an outage:
Canalys includes pad or tablet computers in its PC category calculation, and this was the growth area in PCs. Pad shipments grew by 274% over the past year. Pads accounted for 15% of all client PC shipments. Desktops grew by only two percent over the past year, and notebooks by seven percent.
An Amazon Web Services data center in northern Virginia lost power Friday night during an electrical storm, causing downtime for numerous customers — including Netflix, which uses an architecture designed to route around problems at a single availability zone. The same data center suffered a power outage two weeks ago and had connectivity problems earlier on Friday.Many of Amazon's customers were impacted:
Netflix, Pinterest, Instagram, and Heroku, which run their services atop Amazon's infrastructure cloud, all reported outages because of the power failure.Amazon produced their characteristically informative post-mortem on the event, which explained the cause:
At 7:24pm PDT, a large voltage spike was experienced by the electrical switching equipment in two of the US East-1 datacenters supporting a single Availability Zone. ... In one of the datacenters, the transfer completed without incident. In the other, the generators started successfully, but each generator independently failed to provide stable voltage as they were brought into service. ... servers operated without interruption during this period on the Uninterruptable Power Supply (“UPS”) units. Shortly thereafter, utility power was restored ... The utility power in the Region failed a second time at 7:57pm PDT. Again, all rooms of this one facility failed to successfully transfer to generator power ... all servers continued to operate normally on ... UPS ... power. ... the UPS systems were depleting and servers began losing power at 8:04pm PDT. Ten minutes later, the backup generator power was stabilized, the UPSs were restarted, and power started to be restored by 8:14pm PDT. At 8:24pm PDT, the full facility had power to all racks. ... Approximately 7% of the EC2 instances in the US-EAST-1 Region were ... impacted by the power loss. ... The vast majority of these instances came back online between 11:15pm PDT and just after midnight. Time for the completion of this recovery was extended by a bottleneck in our server booting process. ... The majority of EBS servers had been brought up by 12:25am PDT on Saturday. ... By 2:45am PDT, 90% of outstanding volumes had been turned over to customers. We have identified several areas in the recovery process that we will further optimize to improve the speed of processing recovered volumes.They also provided detailed descriptions of the mechanisms that caused the customer impacts, which should be required reading for anyone building reliable services.
Thursday, July 12, 2012
Preservation as a Cloud Service
I'm not the only one commenting on the "affordable cloud storage" hype that Tesella seems to have swallowed whole as they announce Preservica, their "preservation as a service" competitor for DuraCloud. Via The Register, we find Nati Shalom of Gigaspaces making the fundamental point about cloud economics:
Many people think that cloud economics starts to pay dividends immediately when you move to an on-demand usage model, paying only for what you use. Cloud can actually be fairly expensive when hosting environments in use are not elastic. I was surprised to see how many startups and SaaS organizations still run their applications in the cloud just as they would in any static hosting environment. While the pay-per-use model has a lot of promise for cost-savings if our applications aren’t designed for elasticity the cost of running the application in the cloud may end up costing you more. Most of the mission-critical applications have not been designed for elasticity and on-demand usage.The flaw in the concept of DuraSpace, Preservica and other preservation in the cloud ideas is that digital preservation is the canonical example of a mission-critical application not "designed for elasticity and on-demand usage". The business models of cloud service providers base pricing on the value to their customers of eliminating the over-provisioning needed to cope with peak demand. Digital preservation is a base-load application, it doesn't have peaks and troughs in demand that require over-provisioning.
Matt Asay makes the same point:
But the overall driver of cloud computing, at least for now, is business agility. The early adopters driving cloud computing don't need discounts, because cost isn't their primary motivation. Help them figure out how to do more, faster, and the cost equation of public versus private clouds becomes somewhat of a non-issue.Again, does anyone think the primary need for digital preservation is agility?
Wednesday, June 27, 2012
Cloud vs. Local Storage Costs
In earlier posts I pointed out that for long-term use "affordable cloud storage" wasn't, because compared to local storage:
The model computes the endowment needed to store 135TB of data for 100 years with a 98% chance of not running out of money at various Kryder's Law rates for two cases:
 The graph that the model generates shows that cloud storage is competitive with local storage only if (a) its costs are dropping at least at the same rate as local storage, and (b) both costs are dropping at rates above 30%/yr. Neither is currently the case. If we use the historical 3%/yr at which S3's prices have dropped, and the current disk industry projection of 20%/yr, then the endowment needed for cloud storage is 5 times greater than that needed for local storage.
The graph that the model generates shows that cloud storage is competitive with local storage only if (a) its costs are dropping at least at the same rate as local storage, and (b) both costs are dropping at rates above 30%/yr. Neither is currently the case. If we use the historical 3%/yr at which S3's prices have dropped, and the current disk industry projection of 20%/yr, then the endowment needed for cloud storage is 5 times greater than that needed for local storage.
 UPDATE 3 Sep 12: As I was working to apply our prototype model to Amazon's recently announced Glacier archival storage service, I found two bugs in the simulation that produced the graph above. Fortunately, they don't affect the point I was making, which is that S3 is too expensive for long-term storage, because both tended to under-estimate how expensive it was. Here is a corrected graph, which predicts that S3 would not be competitive with local storage at any Kryder rate.
UPDATE 3 Sep 12: As I was working to apply our prototype model to Amazon's recently announced Glacier archival storage service, I found two bugs in the simulation that produced the graph above. Fortunately, they don't affect the point I was making, which is that S3 is too expensive for long-term storage, because both tended to under-estimate how expensive it was. Here is a corrected graph, which predicts that S3 would not be competitive with local storage at any Kryder rate.
- It was more expensive, and
- It was getting cheaper much slower.
The model computes the endowment needed to store 135TB of data for 100 years with a 98% chance of not running out of money at various Kryder's Law rates for two cases:
- Amazon's S3, starting with their current prices, and assuming no other costs of any kind.
- Maintaining three copies in RAID-6 local storage, starting with BackBlaze's hardware costs adjusted for the 60% increase in disk costs caused by the Thai floods since they were published, and following our normal assumption (based on work from the San Diego Supercomputer Center) that media costs are 1/3 of the total cost of ownership.


Monday, June 4, 2012
Storage Technology Update
Last month marked the 60th anniversary of plastic digital magnetic tape storage.
The IBM 726 digital tape drive was introduced in 1952 to provide larger amounts of digital storage for ... IBM’s 701 computer.As Tom Coughlin points out:
The current generation, LTO 5, has 1.5 TB of native storage capacity. According to Fujifilm and others in the industry, magnetic tape technology can eventually support storage capacities of several 10’s of TB in one cartridge. Much of these increases in storage capacity will involve the introduction of technologies pioneered in the development of magnetic disk drives.While disk drives are coming to the end of the current generation of technology, Perpendicular Magnetic Recording (PMR), tape is still using the previous generation (GMR). So tape technology is about 8 years behind disk, making this forecast is quite credible. And it is possible that by about 2020 the problems of Heat Assisted Magnetic Recording (HAMR) will have been sorted out so that the transition to it will be less traumatic than it is being for the disk industry.
Below the fold I look at disk.
Thursday, May 24, 2012
"Master Class" at Screeing the Future II
Steven Abrams, Matthew Addis and I gave a "master class" on the economics of preservation at the Screening the Future II conference run by PrestoCentre and hosted by USC. Below the fold are the details.
Friday, May 18, 2012
Dr. Pangloss' Notes From Dinner
The renowned Dr. Pangloss greatly enjoyed last night's inaugural dinner of the Storage Valley Supper Club, networking with storage industry luminaries, discussing the storage technology roadmap, projecting the storage market, and appreciating the venue. He kindly agreed to share his notes, which I have taken the liberty of elaborating slightly.
- The following argument was made. The average value to be obtained from a byte you don't keep is guaranteed to be zero. The average cost of not keeping the byte is guaranteed to be zero. Thus the net average value added by not keeping a byte is guaranteed to be zero. But the average value to be obtained from a byte you keep is guaranteed to be greater than zero. The average cost of keeping the byte is guaranteed to be zero. Thus the net average value added by keeping a byte is guaranteed to be greater than zero. So we should keep everything. Happy days for the industry!
- The following numbers were quoted. The number of bytes to be stored is growing at 60%/yr. The cost of storing a byte is growing at -20%. Thus the total cost of storage is growing at
60-20=40(100+60)*(100-20)=128%/yr. And IT budgets are growing 4% a year. Happy days for the industry!
Tip of the hat to Jim Handy for correcting my math.
Monday, May 14, 2012
Lets Just Keep Everything Forever In The Cloud
Dan Olds at The Register comments on an interview with co-director of the Wharton School Customer Analytics Initiative Dr. Peter Fader:
Dr Fader ... coins the terms "data fetish" and "data fetishist" to describe the belief that people and organisations need to capture and hold on to every scrap of data, just in case it might be important down the road. (I recently completed a Big Data survey in which a large proportion of respondents said they intend to keep their data “forever”. Great news for the tech industry, for sure.)The full interview is worth reading, but I want to focus on one comment, which is similar to things I hear all the time:
But a Big Data zealot might say, "Save it all—you never know when it might come in handy for a future data-mining expedition."Follow me below the fold for some thoughts on data hoarding.
Monday, May 7, 2012
Harvesting and Preserving the Future Web
Kris Carpenter Negulescu of the Internet Archive and I organized a half-day workshop on the problems of harvesting and preserving the future Web during the International Internet Preservation Coalition General Assembly 2012 at the Library of Congress. My involvement was spurred by my long-time interest in the evolution of the Web from a collection of linked documents whose primary language was HTML to a programming environment whose primary language is Javascript.
In preparation for the workshop Kris & I, with help from staff at the Internet Archive, put together a list of 13 problem areas already causing problems for Web preservation:
But the clear message from the workshop is that the old goal of preserving the user experience of the Web is no longer possible. The best we can aim for is to preserve a user experience, and even that may in many cases be out of reach. An interesting example of why this is so is described in an article on A/B testing in Wired. It explains how web sites run experiments on their users, continually presenting them with randomly selected combinations of small changes as part of a testing program:
In preparation for the workshop Kris & I, with help from staff at the Internet Archive, put together a list of 13 problem areas already causing problems for Web preservation:
- Database driven features
- Complex/variable URI formats
- Dynamically generated URIs
- Rich, streamed media
- Incremental display mechanisms
- Form-filling
- Multi-sourced, embedded content
- Dynamic login, user-sensitive embeds
- User agent adaptation
- Exclusions (robots.txt, user-agent, ...)
- Exclusion by design
- Server-side scripts, RPCs
- HTML5
But the clear message from the workshop is that the old goal of preserving the user experience of the Web is no longer possible. The best we can aim for is to preserve a user experience, and even that may in many cases be out of reach. An interesting example of why this is so is described in an article on A/B testing in Wired. It explains how web sites run experiments on their users, continually presenting them with randomly selected combinations of small changes as part of a testing program:
Use of a technique called multivariate testing, in which myriad A/B tests essentially run simultaneously in as many combinations as possible, means that the percentage of users getting some kind of tweak may well approach 100 percent, making “the Google search experience” a sort of Platonic ideal: never encountered directly but glimpsed only through imperfect derivations and variations.It isn't just that one user's experience differs from another's. The user can never step into the same river twice. Even if we can capture and replay the experience of stepping into it once, the next time will be different, and the differences may be meaningful, or random perturbations. We need to re-think the whole idea of preservation.
Tuesday, May 1, 2012
Catching up
This time I'm not going to apologise for the gap in posting; I was on a long-delayed vacation. Below the fold are some links I noticed in the intervals between vacating.
Monday, March 12, 2012
What Is Peer Review For?
Below the fold is an edited version of a talk I prepared for some discussion of the future of research communication at Stanford, in which I build on my posts on What's Wrong With Research Communication? and What Problems Does Open Access Solve? to argue that the top priority for reform should be improving peer review.
Saturday, February 25, 2012
Talk at PDA2012
I spoke at this year's Personal Digital Archiving conference at the Internet Archive, following on from my panel appearance there a year ago. Below the fold is an edited text of the talk with links to the sources.
Wednesday, February 22, 2012
FAST 2012
We gave a work-in-progress paper (PDF) and a well-received poster (PDF) on our economic modeling work at the 2012 FAST conference. As usual, the technical sessions featured some very interesting papers, although this year it was hard to find any relevant to long-term storage. Below the fold are notes on the papers that caught my eye.
Friday, February 17, 2012
Cloud Storage Pricing History
The original motivation for my work on the economics of long-term storage was to figure out whether it made sense to use cloud storage for systems such as LOCKSS. Last December I finally got around to looking at the history of Amazon S3's pricing, and I was surprised to see that in nearly 6 years the price for the first TB had dropped from $0.15/GB/mo to $0.14/GB/mo. Since then, Amazon has dropped the price to $0.125/GB/mo, so the average drop in price is now about 3%/yr.
I wondered whether this very slow price drop was representative of the cloud storage industry in general, so I went looking. Below the fold is what I found, and some of the implications for cloud use for long-term storage.
I wondered whether this very slow price drop was representative of the cloud storage industry in general, so I went looking. Below the fold is what I found, and some of the implications for cloud use for long-term storage.
Tuesday, February 7, 2012
Tide Pools and Terrorists
There's an article in the current issue of Stanford's alumni magazine that discusses, in a very accessible way, many of the concepts people need to think about when designing systems for long-term digital preservation. Raphael D. Sagarin has evolved from studying how organisms in the Monterey tide pools adapt to climate change, to critiquing responses to terrorist incidents. He suggests we have a lot to learn from the way organisms respond and adapt to threats. For example:
The whole article is worth a careful read, as is Sagarin's Adapt or Die article in Foreign Policy.
STRATEGY 1: Embrace uncertainty. In the natural world, they argue, most species increase uncertainty for their enemies by deploying multiple strategies for attack or defense. Think of the octopus, says Sagarin: "It's got an ink cloud it can use; it's got a beak it can use; some of them have poison; they've got these suckers; it's got really good camouflage." If one strategy doesn't work, it can fall back on another.Increasing uncertainty for the enemy is one major aspect of the defenses of the LOCKSS system. The more you increase your certainty about what your preservation system is doing, the easier you make it for an enemy or an error to affect large parts of the system. In the long term, randomization is your friend. So is:
STRATEGY 2: Decentralize. "Putting homeland security in the hands of a massive, plodding bureaucracy hardly represents evolutionary advancement," ... Sagarin's ideal defense would operate more like the human immune system—with units that react semiautonomously to threats, loosely governed by a central command. "Instead of relying on a centralized brain or controller for everything, you farm out the responsibility of searching for and responding to changes in the environment to many, many different agents," he says.LOCKSS boxes are autonomous, only loosely coordinated, in exactly this manner. The more coordinated the behavior of the parts of your system, the more correlated are the failures.
The whole article is worth a careful read, as is Sagarin's Adapt or Die article in Foreign Policy.
Thursday, February 2, 2012
Domain Name Persistence
Last December a useful workshop on Domain Name Persistence was held in conjunction with the 7th International Digital Curation Conference. My comments on the need for persistent domain names are below the fold.
Tuesday, January 31, 2012
The 5 Stars of Online Journal Articles
David Shotton, another participant in last summer's Dagstuhl workshop on Future of Research Communications, has an important article in D-Lib entitledThe Five Stars of Online Journal Articles — a Framework for Article Evaluation. By analogy with Tim Berners-Lee's Five Stars of Linked Open Data, David suggests assessing online articles against five criteria:
The article concludes by applying the evaluation to a number of articles (including itself). In this spirit, here is my evaluation of our SOSP '03 paper:
- peer review
- open access
- enriched content
- available datasets
- machine-readable metadata
The article concludes by applying the evaluation to a number of articles (including itself). In this spirit, here is my evaluation of our SOSP '03 paper:
- peer review: 2 - Responsive peer review
- open access: 1 - Self-archiving green/gratis open access
- enriched content: 1 - Active Web links
- available datasets: 1 - Supplementary information files available
- machine-readable metadata: 1- Structural markup available
Friday, January 27, 2012
Yahoo's HTML5 Tools
Last August I wrote about the way HTML5 would accelerate the transition of the Web from static to dynamic content, from a document model to a programming environment. Now, via Slashdot, we learn of Yahoo's plans to open-source most of their tools for publishing HTML5. Details below the fold.
Friday, January 20, 2012
Mass-Market Scholarly Communication Revisted
The very first post to this blog in 2007 was entitled "Mass-Market Scholarly Communication". Its main point was:
It was developed based on experience with PLOS Currents, a rapid publishing journal hosted at Google. After a detailed review of the alternatives, the developers decided to implement Annotum as a WordPress theme providing the capabilities needed for journal publishing, such as multiple authors, strict adherence to JATS (the successor to the NLM DTD), tables, figures, equations, references and review. The leverage of mass-market publishing technology is considerable. The paper describing Annotum is well worth a read.
Blogs are bringing the tools of scholarly communication to the mass market, and with the leverage the mass market gives the technology, may well overwhelm the traditional forms.Now, Annotum: An open-source authoring and publishing platform based on WordPress is proving me a prophet.
It was developed based on experience with PLOS Currents, a rapid publishing journal hosted at Google. After a detailed review of the alternatives, the developers decided to implement Annotum as a WordPress theme providing the capabilities needed for journal publishing, such as multiple authors, strict adherence to JATS (the successor to the NLM DTD), tables, figures, equations, references and review. The leverage of mass-market publishing technology is considerable. The paper describing Annotum is well worth a read.
Subscribe to:
Posts (Atom)