 Because Nvidia became one of the most valuable companies in the world, there are now two books explaining its rise and extolling the genius of Jensen Huang, Tae Kim's The Nvidia Way: Jensen Huang and the making of a tech giant, and Steven Witt's The Thinking Machine: Jensen Huang, Nvidia, and the World's Most Coveted Microchip. For the later 90% of the history I wasn't there, so I won't comment on their treatment of that part. But for the pre-history at Sun Microsystems and the first 10% of the history I was there. Kim's account of the business side of this era is detailed and, although it was three decades ago, matches my recollections.
Because Nvidia became one of the most valuable companies in the world, there are now two books explaining its rise and extolling the genius of Jensen Huang, Tae Kim's The Nvidia Way: Jensen Huang and the making of a tech giant, and Steven Witt's The Thinking Machine: Jensen Huang, Nvidia, and the World's Most Coveted Microchip. For the later 90% of the history I wasn't there, so I won't comment on their treatment of that part. But for the pre-history at Sun Microsystems and the first 10% of the history I was there. Kim's account of the business side of this era is detailed and, although it was three decades ago, matches my recollections. Witt's account of the business side of the early history is much less detailed and some of the details don't match what I remember.
Witt's account of the business side of the early history is much less detailed and some of the details don't match what I remember.But as regards the technical aspects of this early history it appears that neither author really understood the reasons for the two kinds of innovation we made; the imaging model and the I/O architecture. Witt writes (Page 31):
The first time I asked Priem about the architecture of the NV1, he spoke uninterrupted for twenty-seven minutes.Below the fold, I try to explain what Curtis was talking about for those 27 minutes. It will take me quite a long post.
Background
 |
| NV1-based Diamond Edge Swaaye, CC-By-SA 3.0 |
The opportunity we saw when we started Nvidia was that the PC was transitioning from the PC/AT bus to version 1 of the PCI bus. The PC/AT bus' bandwidth was completely inadequate for 3D games, but the PCI bus had considerably more. Whether it was enough was an open question. We clearly needed to make the best possible use of the limited bandwidth we could get.We had two basic ways of making "the best possible use of the limited bandwidth":
- Reduce the amount of data we needed to ship across the bus for a given image.
- Increase the amount of data shipped in each cycle of the bus.
Imaging Model
A triangle is the simplest possible description of a surface. Thus almost the entire history of 3D computer graphics has modeled the surfaces of 3D objects using triangles. But there is a technique, dating back at least to Robert Mahl's 1972 paper Visible Surface Algorithms for Quadric Patches, for modeling curved surfaces directly. It takes a lot more data to describe a quadric patch than a triangle. But to achieve equivalent realism you need so many fewer patches that the amount of data for each frame is reduced by a significant factor. |
| Virtua Fighter on NV1 |
At Sun, James Gosling and I built the extremely sophisticated and forward-looking but proprietary NeWS window system. At the same time, I also worked with engineers at competitors such as Digital Equipment to build the X Window System. One of my many learning experiences at Sun came early in the long history of the X Window System. It rapidly became obvious to me that there was no way NeWS could compete with the much simpler, open-source X. I argued for Sun to open-source NeWS and failed. I argued for Sun to drop NeWS and adopt X, since that was what application developers wanted. Sun wasted precious time being unable to decide what to do, finally deciding not to decide and wasting a lot of resource merging NeWS and X into a kludge that was a worse NeWS and a worse X than its predecessors. This was just one of a number of fights at Sun I lost (this discusses another).
Once Microsoft announced Direct X it was obvious to me that Nvidia was doomed if the next chip did quadric patches, because the developers would have to work with Direct X's triangles. But, like Sun, Nvidia seemed unable to decide to abandon its cherished technology. Time for a decision to be effective was slipping away. I quit, hoping to shake things up so as to enable a decision to do things Microsoft's way. The books recount how close Nvidia was to bankruptcy when RIVA 128 shipped. The rest is history for which I was just an observer.
I/O Architecture
In contrast the I/O architecture was, over time, the huge success we planned. Kim writes (Page 95):Early on, Curtis Priem had invented a "virtualized objects" architecture that would be incorporated in all of Nvidia's chips. It became an even bigger advantage for the company once Nvidia adopted the faster cadence of chip releases. Priem's design had a software based "resource manager", essentially a miniature operating system that sat on top of the hardware itself. The resource manager allowed Nvidia's engineers to emulate certain hardware features that normally needed to be physically printed onto chip circuits. This involved a performance cost but accelerated the pace of innovation, because Nvidia's engineers could take more risks. If the new feature wasn't ready to work in the hardware, Nvidia could emulate it in software. At the same time, engineers could take hardware features out when there was enough leftover computing power, saving chip area.
For most of Nvidia's rivals, if a hardware feature on a chip wasn't ready, it would mean a schedule slip. Not, though, at Nvidia, thanks to Priem's innovation. "This was the most brilliant thing on the planet," said Michael Hara. "It was our secret sauce. If we missed a feature or a feature was broken, we could put it in the resource manager and it would work." Jeff Fisher, Nvidia's head of sales, agreed: "Priem's architecture was critical in enabling Nvidia to design and make new products faster."
Context
 |
| Sun GX version 1 |
The GX team also learned from the difficulty of shipping peripherals at Sun, where the software and hardware schedules were inextricable because the OS driver and apps needed detailed knowledge of the physical hardware. This led to "launch pad chicken", as each side tried to blame schedule slippage on the other.
Write-mostly
Here is how we explained the problem in US5918050A: Apparatus accessed at a physical I/O address for address and data translation and for context switching of I/O devices in response to commands from application programs (inventors David S. H. Rosenthal and Curtis Priem), using the shorthand "PDP11 architecture" for systems whose I/O registers were mapped into the same address space as system memory:Not only do input/output operations have to be carried out by operating system software, the design of computers utilizing the PDP11 architecture usually requires that registers at each of the input/output devices be read by the central processing unit in order to accomplish any input/output operation. As central processing units have become faster in order to speed up PDP11 type systems, it has been necessary to buffer write operations on the input/output bus because the bus cannot keep up with the speed of the central processing unit. Thus, each write operation is transferred by the central processing unit to a buffer where it is queued until it can be handled; other buffers in the line between the central processing unit and an input/output device function similarly. Before a read operation may occur, all of these write buffers must be flushed by performing their queued operations in serial order so that the correct sequence of operations is maintained. Thus, a central processing unit wishing to read data in a register at an input/output device must wait until all of the write buffers have been flushed before it can gain access to the bus to complete the read operation. Typical systems average eight write operations in their queues when a read operation occurs, and all of these write operations must be processed before the read operation may be processed. This has made read operations much slower than write operations. Since many of the operations required of the central processing unit with respect to graphics require reading very large numbers of pixels in the frame buffer, then translating those pixels, and finally rewriting them to new positions, graphics operations have become inordinately slow. In fact, modern graphics operations were the first operations to disclose this Achilles heel of the PDP11 architecture.
 |
| '930 Figure 3 |
Second, we tried as far as possible not to use the CPU to transfer data to and from NV1. Instead, whenever we could we used Direct Memory Access, in which the I/O device reads and writes system memory independently of the CPU. In most cases, the CPU instructed NV1 to do something with one, or a few writes, and then got on with its program. The instruction typically said "here in memory is a block of quadric patches for you to render". If the CPU needed an answer, it would tell NV1 where in system memory to put it and, at intervals, check to see if it had arrived.
Remember that we were creating this architecture for a virtual memory system in which applications had direct access to the I/O device. The applications addressed system memory in virtual addresses. The system's Memory Management Unit (MMU) translated these into the physical addresses that the bus used. When an application told the device the address of the block of patches, it could only send the device one of its virtual addresses. To fetch the patches from system memory, the DMA engine on the device needed to translate the virtual address into a physical address on the bus in the same way that the CPU's MMU did.
So NV1 didn't just have a DMA engine, it had an IOMMU as well. We patented this IOMMU as US5758182A: DMA controller translates virtual I/O device address received directly from application program command to physical i/o device address of I/O device on device bus (inventors David S. H. Rosenthal and Curtis Priem). In 2014's Hardware I/O Virtualization I explained how Amazon ended up building network interfaces with IOMMUs for the servers in AWS data centers so that mutiple virtual machines could have direct access to the network hardware and thus eliminate operating system overhead.
Context switching
The fundamental problem for graphics support in a multi-process operating system such as Unix (and later Linux, Windows, MacOS, ...) is that of providing multiple processes the illusion that each has exclusive access to the single graphics device. I started fighting this problem in 1983 at Carnegie-Mellon. James Gosling and I built the Andrew Window System, which allowed multiple processes to share access to the screen, each in its own window. But they didn't have access to the real hardware. There was a single server process that accessed the real hardware. Applications made remote procedure calls (RPCs) to this server, which actually drew the requested graphics. Four decades later the X Window System still works this way.RPCs imposed a performance penalty that made 3D games unusable. To allow, for example, a game to run in one window while a mail program ran in another we needed the currently active process to have direct access to the hardware, and if the operating system context-switched to a different graphics process, give that process direct access to the hardware. The operating system would need to save the first process' state from the graphics hardware, and restore the second process' state
Our work on this problem at Sun led to a patent filed in 1989, US5127098A: Method and apparatus for the context switching of devices (inventors David S. H. Rosenthal, Robert Rocchetti, Curtis Priem, and Chris Malachowsky). The idea was to have the device mapped into each process' memory but to use the system's memory management unit (MMU) to ensure that at any one time all but one of the mappings was invalid. A process' access to an invalid mapping would interrupt into the system's page fault handler, which would invoke the device's driver to save the old process' context and restore the new process' context. The general problem with this idea is that, because the interrupt ends up in the page fault handler, it requires device-dependent code in the page fault handler. This is precisely the kind of connection between software and hardware that caused schedule problems at Sun.
There were two specific Nvidia problems with this idea. First that Windows wasn't a virtual memory operating system so you couldn't do any of this. And second that even once Windows had evolved into a virtual memory operating system, Microsoft was unlikely to let us mess with the page fault handler.
 |
| '930 Figure 6 |
{kind=link}
- It implemented the FIFO, sharing it among all the devices on the internal bus.
- It implemented the DMA engine and its IOMMU, sharing it among all the devices on the internal bus.
- Using a translation table, it allowed applications to connect to a specific device on the internal bus via the interface using a virtual name.
- It ensured that only one application at a time could access the interface.
the use of many identically-sized input/output device address spaces each assigned for use only by one application program allows the input/output addresses to be utilized to determine which application program has initiated any particular input/output write operation.Because applications each saw their own virtual FIFO, future chips could implement multiple physical FIFOs, allowing the virtual FIFO of more than one process to be assigned a physical FIFO, which would reduce the need for context switching.
Objects & Methods
 |
| Don's NeWS Pie Menu |
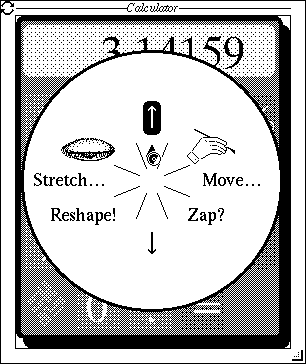{kind=link}
At a time when PC memory maxed out at 640 megabytes, the fact that the PCI bus could address 4 gigabytes meant that quite a few of its address bits were surplus. So we decided to increase the amount of data shipped in each bus cycle by using some of them as data. IIRC NV1 used 23 address bits, occupying 1/512th of the total space. 7 of the 23 selected one of the 128 virtual FIFOs, allowing 128 different processes to share access to the hardware. We figured 128 processes was plenty.
 |
| '930 Figures 4,5 |
{kind=link}
So we organized the objects in our I/O architecture in a class hierarchy, rooted at class CLASS. The first thing an application did was to invoke the enumerate() method on the object representing class CLASS. This returned a list of the names of all the instances of class CLASS, i.e. all the object types this instance of the architecture implemented. In this way capabilities of the device weren't wired in to the application. The application asked the device what its capabilities were. In turn, the application could invoke enumerate() on each of the instances of class CLASS in the list, which would get the application a list of the names of each of the instances of each class, perhaps LINE-DRAWER.Thus the application would find out rather than know a priori the names of all the resources (virtual objects) of all the different types that the device supported.
The application could then create objects, instances of these classes, by invoking the instantiate() method on the class object with a 32-bit name for the newly created object. The interface was thus limited to 4B objects for each application. The application could then select() the named object, causing an interrupt if there was no entry for it in the translation table so the resource manager could create one. The 64Kbyte address space of each FIFO was divided into 8 8K "sub-areas". The application could select() an object in each, so it could operate on 8 objects at a time. Subsequent writes to each sub-area were interpreted as method invocations on the selected object, the word offset from the base of each sub-area within the 8Kbyte space specifying the method and the data being the argument to the method. The interface thus supported 2048 different methods per object.
In this way we ensured that all knowledge of the physical resources of the device was contained in the resource manager. It was the resource manager that implemented class CLASS and its instances. Thus it was that the resource manager controlled which instances of class CLASS (types of virtual object) were implemented in hardware, and which were implemented by software in the resource manager. It was possible to store the resource manager's code in read-only memory on the device's PCI card, inextricably linking the device and its resource manager. The only thing the driver for the board needed to be able to do was to route the device's interrupts to the resource manager.
The importance of the fact that all an application could do was to invoke methods on virtual objects was that the application could not know whether the object was implemented in hardware or in the resource manager's software. The flexibility to make this decision at any time was a huge advantage. As Kim quotes Michael Hara as saying:
This was the most brilliant thing on the planet. It was our secret sauce. If we missed a feature or a feature was broken, we could put it in the resource manager and it would work."
Conclusion
As you can see, NV1 was very far from the "minimal viable product" beloved of today's VCs. Their idea is to get something into users' hands as soon as possible, then iterate rapidly based on their feedback. But what Nvidia's VCs did by giving us the time to develop a real chip architecture was to enable Nvidia, after the failure of the first product, to iterate rapidly based on the second. Iterating rapidly on graphics chips requires that applications not know the details of successive chip's hardware.I have been privileged in my career to work with extraordinarily skilled engineers. Curtis Priem was one, others included James Gosling, the late Bill Shannon, Steve Kleiman, and Jim Gettys. This search returns 2 Sun patents and 19 Nvidia patents for which both Curtis Priem and I are named inventors. Of the Nvidia patents, Curtis is the lead inventor on 9 and I am the lead inventor on the rest. Most describe parts of the Nvidia architecture, combining Curtis' exceptional understanding of hardware with my understanding of operating systems to redefine how I/O should work. I rate this architecture as my career best engineering. It was certainly the most impactful. Thank you, Curtis!
3 comments:
The design here is a good case of actually anticipating the future developments of technology (virtual FIFOs would seem to be genius from my point of view). I'm working on an NV3, eventually NV1/NV4, emulation (currently got 2D working which is a giant pain), and it's a pain in the ass to emulate this stuff. Did you work on NV2/the original 1996 QTM NV3/Riva 128? Also, was NV0 a set of VxDs that emulated the architecture?
The discussion on Hacker News includes a worthwhile contribution from Don Hopkins and some useful links about the GX.
In CUDA Proves Nvidia Is a Software Company Sheon Han explains:
"The company that does have a moat is Nvidia. CEO Jensen Huang has called it his most precious “treasure.” It is not, as you might assume for a chip company, a piece of hardware. It’s something called CUDA. What sounds like a chemical compound banned by the FDA may be the one true moat in AI.
CUDA technically stands for Compute Unified Device Architecture,"
CUDA is a strange name for software but the reason it is called that is because it is based upon Nvidia's UDA, Unified Device Architecture, the architecture Curtis and I developed that is described in this post. Han's post is well worth reading.
Post a Comment