Anti-trust investigations of the FAANGs are all over the recent headlines. First came Facebook, as Nina Golgowski reported in New York To Investigate Facebook Over Possible Antitrust Violations:
New York Attorney General Letitia James is launching a joint, multistate investigation into possible antitrust violations committed by Facebook, she announced Friday.And Amazon, as Spencer Soper and Ben Brody reported in Amazon Probed by U.S. Antitrust Officials Over Marketplace:
The investigation will examine “Facebook’s dominance in the industry and the potential anti-competitive conduct stemming from that dominance,” her office said in a press release. It will include the attorneys general of Colorado, Florida, Iowa, Nebraska, North Carolina, Ohio, Tennessee and the District of Columbia.
A team of Federal Trade Commission investigators has begun interviewing small businesses that sell products on Amazon.com Inc. to determine whether the e-commerce giant is using its market power to hurt competition.Then came Google, as Kate Cox reported in 50 states and territories launch massive joint probe into Google:
A coalition of attorneys general representing 50 US states and territories today announced a long-awaited joint probe into antitrust complaints against one of the biggest tech companies in the world, Google.But, as Cox pointed out, the state AGs are late to the game:
The office of Texas Attorney General Ken Paxton is spearheading the bipartisan investigation, which is beginning with the search and digital advertising markets. Google "dominates all aspects of advertising on the Internet and searching on the Internet," Paxton told reporters during a press conference.
The group includes attorneys general from 48 states, Puerto Rico, and the District of Columbia. (Alabama and California are the two states not participating.) The states' action is independent of several different federal actions, participating attorneys general stressed.
The Justice Department publicly confirmed in July its antitrust division was digging into widespread "concerns that consumers, businesses, and entrepreneurs have expressed" about "market-leading online platforms." The agency, which rarely comments publicly on pending probes, didn't name names, but several media reports have suggested that the DOJ and Federal Trade Commission agreed to split the big antitrust work this year, with the DOJ taking on Apple and Google while the FTC looks at Amazon and Facebook.In Big Tech Meets Its Pecora Commission: Why Google's Toughest Opponent Is Now Congress, Matt Stoller is giddy with anticpation about the information that will be exposed about Google's internal workings. It is really unlikely that all of these investigations will conclude that no illegal behavior took place. So at least some of these authorities will need to take enforcement actions, but Stoller has nothing to say about what, and how effective, they might be. Or, for that matter, why, if Google and the other FAANGs are important targets of anti-trust investigation, the oligopoly telcos aren't.
...
The FTC has been contemplating antitrust action against Google for the better part of a decade. In 2012, a memo circulated to all five commissioners strongly recommended launching an antitrust suit against Google for abusing its dominance. In 2013, the commission voted against bringing charges, leading to several years of criticism.
The European Commission's competition bureau, which handles antitrust matters for the European Union, has fined Google billions of dollars across three years for antitrust violations. First came a then-record-breaking €2.42 billion fine in 2017 for steering shoppers toward Google's platform in search results. That record was then broken in 2018 with a €4.34 billion fine for unfairly pushing its own apps ahead of competitors', and those two fines were joined by another €1.5 billion this year for abusing its dominant position in the ad sales market.
...
Facebook also confirmed in July that it is under antitrust investigation by the FTC, and last week a coalition of attorneys general representing eight states and the District of Columbia also launched a probe, led by Attorney General Letitia James of New York.
Amazon, too, is at the heart of a boatload of investigations. Retailers have all but begged for US regulators to take strong action, joining Germany, Austria, Italy, and the European Union, which all have their own antitrust probes going on right now.
Congress in June launched a bipartisan investigation looking at "competition in digital markets." The investigation — which has probed Facebook, Google, and Amazon so far — went quiet during the traditional August recess, but several hearings on the topic are slated for later this month.
Apple is also reportedly the target of investigations. Music-streaming service Spotify lodged a complaint with the EU about Apple's app-store behavior. The Congressional probe also started asking about Apple's position on consumers' right to repair their own devices as part of its work.
I've expressed general skepticism about the weapons in anti-trust arsenals, for example in It's The Enforcement, Stupid!, and enforcement so far doesn't seem to have deterred the public from using the FAANGs. €8.26 billion in fines over the last three years hasn't had much effect on Google, so now I want to look in detail at whether, supposing the US administration wanted to take action against Google, what they could do.
Is Google A Monopoly?
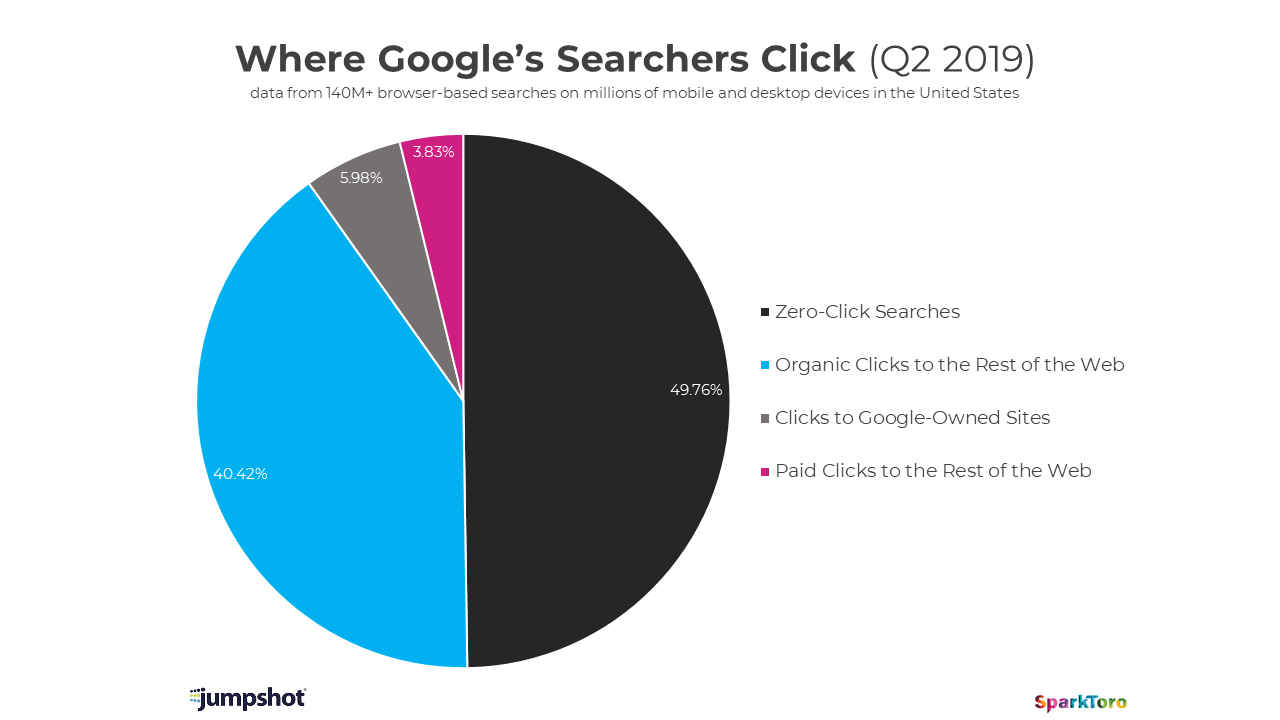
In Less than Half of Google Searches Now Result in a Click Rand Fishkin persuasively argues that:- Google's share of US search queries is at least 94% and probably 97%.
- Google's share of the traffic resulting from US searches is over 55% and probably higher.
Fishkin's data comes from Jumpshot, and at the end of the post he explains why he thinks it is realistic:
Jumpshot’s panel worldwide is over 100 million devices. In the United States alone, it’s in the many millions (though Jumpshot keeps the precise size private). By my estimates (Rand’s best guess, not Jumpshot’s) it’s somewhere between 2-6% of the total number of mobile and desktop Internet-browsing devices in the US, AKA a statistically significant sample size. Undoubtedly, this device panel has biases — perhaps iOS users (which aren’t counted) search more often on average, or click on results more often when they do search. Maybe Jumpshot’s panel of users is slightly more likely to use Google or less likely to use Bing than the average web user.
But, overall, it’s likely these biases are small (a few percentage points at most). And so far, I haven’t seen evidence of any bias that suggests the way Jumpshot’s users search and click is different from the way any other group of web browsers is.
 |
| Source |
That’s because mobile apps, which Jumpshot doesn’t currently measure, aren’t included — this is just browser-based search data. The Google Maps App, Google Search App, and YouTube are installed on almost every mobile device in the US, and likely have so much usage that, if their search statistics were included, Google’s true market share would be 97%+.As the chart's caption notes, the fact that app-based searches are not captured also biases some non-Google sites lower, including Amazon (#4), Facebook (#7) and Twitter (#10). But it unlikely that these cancel out searches via Google's apps.
 |
| Source |
what is meant by a “Zero-click” search.Another 5.98% of searches result in a visit to another Google site, leading to the 55% number. Note that this means that around 12% of all visits generated by search don't leave Google's fenced garden.
- The most literal definition is a search that results in zero website referrals, i.e. no web property receives a visit from the search.
- Searches that are answered by the results, searches that end because a user was frustrated and couldn’t find an answer, searches that end because something interrupted the searcher, or any other reason for a cessation of activity after the query would all count as “zero click” searches.
- Because Jumpshot only measures browser behavior, a click/action that takes a searcher out of the browser (for example, opening the phone app for a click-to-call, or the Google Maps app for driving directions) will be categorized under zero-click searches.
- Voice searches that show a screen of results are part of this analysis. Searches that are answered by a device’s audio (like Alexa, Siri, Google Assistant, etc. speaking an answer) are not counted.
How Did Google Achieve Dominance?
Google wasn't the first, but when it launched in the early days of Web search engines it was clearly much better than the competition, for two main reasons:- Page-rank meant that their results were significantly more relevant than the competition's.
- Low tail latency meant that their perceived performance was significantly better than the competition's.
The fact is that for US Web users search and Google are synonymous. That is what sustains Google's massive share of US Web search.
Suggested Anti-Trust Remedies
Clearly, a company with a 94+% market share allowing others only 45-% of the available traffic is ripe for anti-trust action. Traditionally, there are two broad approaches to anti-trust remedies, breakup and regulation. For example, Steve Lohr's How Should Big Tech Be Reined In? Here Are 4 Prominent Ideas discusses two forms of breakup:- Bright-Line Breakups - the idea is a simple one with a history in anti-trust dating back to the railroads:
If you own a dominant online marketplace or platform, you cannot also offer the goods, services and software applications sold on that marketplace.
This approach is a necessary but not sufficient part of addressing Amazon's monopoly. The world can live without Amazon's clones of other companies' products. But it is much less appropriate for other tech monopolies, such as Facebook. I do think bright lines are important; in It's The Enforcement, Stupid! and Lina M. Khan On Structural Separation I've written about how they make enforcement much easier. But this bright line, which Lina Khan calls "structural separation", can't be the only one.
So Amazon could not own the leading e-commerce marketplace and sell Amazon-label goods there. Or Google could not have both the dominant search engine and its Google Shopping service, which shows up in search results. Apple could own an app store that offers music services, but not also its own music service sold there. - Selective Split-Ups - this is the approach that led to the breakup of AT&T and the government's case against Microsoft:
This is a case-by-case approach to breakups rather than a broad rule applied to all the tech giants. A current example is a plan that would require Facebook to shed Instagram and WhatsApp. A detailed proposal on this, laying out the alleged anticompetitive conduct, was developed by two leading antitrust scholars, Tim Wu of Columbia Law School and Scott Hemphill of New York University Law School, along with Chris Hughes, a co-founder of Facebook.
This approach could split AWS away from Amazon, likely to the benefit of holders of AMZN. It isn't clear that (AMZN - AWS) would be less of a monopoly. As applied to Facebook, it might be that Instagram would be an effective competitor, but network effects are so powerful in social media that it might die. If WhatsApp is to continue using end-to-end encryption and become a stand-alone business it would likely be unable to sell enough advertisements, and would need to charge a subscription, which would likely not be viable.
- A New Tech Watchdog, since the ones we have are clearly clueless or captured:
One idea is the creation of a new regulator, a Digital Authority. It would be an expert group to supplement traditional antitrust regulators in the Justice Department and the Federal Trade Commission. It would be able to move faster and have the expertise to constantly track the tech markets and trends.
The 737 MAX fiasco illustrates both how common and how dangerous regulatory capture is.
...
The new regulator was the central recommendation of a recent report about the digital platforms that was sponsored by the Stigler Center for the Study of the Economy and the State at the University of Chicago. - Unlock the Data has been a rallying cry for some time, especially in the decentralized Web community:
There are also narrower, targeted regulatory proposals. Some of these involve rules that would loosen a dominant company’s control of user data, by either forcing that company to share the data with a smaller competitor or giving users more ability to take their data from one service and move it to a competitor. The Stigler Center study cited those data moves in a list of potential regulations and enforcement actions.
The proposals fall short of the decentralized Web goal, which is that people own the data about them, a concept with some logical difficulties because each Web interaction generates data both at the client and at the server.
One solution would be to convert some of these infrastructures into “public options”—publicly managed alternatives to private provision. Run by the state, these public versions could operate on equitable, inclusive, and nondiscriminatory principles. Public provision of these infrastructures would subject them to legal requirements for equal service and due process. Furthermore, supplying a public option would put competitive pressures on private providers.But he fails to explain how users would be persuaded to use the public infrastructure instead of the commercial monopolist.
It is hard to believe any of these are feasible without a change of control in both Presidency and Senate, a purge of Federalist Society judges, public funding of elections with UK-style limits on spending, and a major reconstruction of the Federal bureaucracy. But, in the light of Fishkin's data, even if we imagine that these have happened, it is equally hard to believe any of them would be effective in creating a competitive information ecosystem.
Much of the discussion about anti-trust remedies focuses on Amazon and Facebook, but they are the easy cases. Amazon, both because the voters are actually Amazon customers, and because the harm Amazon's monopoly is doing can be seen in the shuttered storefronts on Main Street. Facebook, because the Cambridge Analytica and related scandals directly impact politicians, who are customers of Facebook as they spend much of their re-election budget. But I think the hard case is Google, because neither voters nor politicians are significant paying customers, and the harm that Google's monopoly of search does is much harder to see than Amazon's or Facebook's harm. So lets look at applying the proposed remedies to Google.
Breaking Up Google?
The problem with Selective Split-Ups as applied to Google is that it really has only one viable business, search advertising. YouTube is the next biggest component and it isn't clear that it is even profitable. Andrew Beattie writes in How YouTube Makes Money Off Videos:How does YouTube make money off of your videos? And does it make money at all, at least if we are talking about profit rather than just revenue? Once you consider the rising payouts for content, the cost of hosting all those videos and the fact that YouTube gets paid according to how much of an ad is viewed, the conclusion could be that YouTube is struggling to make a profit.In 2017, the last year YouTube revenue was reported separately, it made less than 10% of Google's total revenue ($9B out of $110B). Despite being linked from Andreessen Horowitz, more recent claims are suspect:
Using Fishkin's numbers, without YouTube and Google Maps, Google would still have 89.8% of the search market. Shorn of all its other businesses, Google would still be a monopoly.
- The Annual cost of running and maintaining YouTube is $6,350,000,000.
- Google’s annual revenue generated from YouTube is $4,000,000,000.
- Youtube generates 6% of Google’s ad sales revenue.
The other businesses would probably die. The world might survive without YouTube's cat videos. Google Maps has competition from Apple and even OpenStreetMap. But a world without Android would be an Apple monopoly.
If the search part of Google were a stand-alone company, would it have effective competition? Bing is the obvious candidate for a competitor. How could Microsoft get Bing competitive with Google in US search? It is really hard to see a way:
- They could become a so much better search engine that users made the effort to choose Bing over Google. Web search is a mature technology; a technological breakthrough[1] capable of doing this is unlikely, and Microsoft could in practice not prevent Google from copying it.
- They could mount a massive advertising campaign, but the immense investment needed wouldn't pay dividends.
Google’s search engine dominance can seem invincible, but that doesn’t mean the search giant isn’t willing to pay billions to ensure it stays that way.It may look like Google is spending $12B/year to "buy traffic", but another way to looking at it is that they are setting the entry price for a competitor high enough that, lacking Google's monopoly rents, no competitor would find it a viable investment.
Google will reportedly pay Apple $9 billion in 2018 and $12 billion in 2019 to remain as Safari’s default search engine, according to Business Insider. The report comes courtesy of Goldman Sachs analyst Rod Hall. It seems like a hefty price to pay, but with Safari being the default browser on iPhone, iPads, and Macs—and Google continuing to generate a great deal of revenue from its original search engine business—the Goldman Sachs report finds the payments to be a fraction of the money it ends up making.
The problem with Bright-Line Breakups as applied to Google is that Google sells advertising to others but doesn't advertise much itself. Sure, it sells a few products and services that it can preferentially advertise on its platform, but they are an insignificant part of its business. They were actually fined by the EU for favoring their own shopping service in search results, but do you even know anyone who would notice if Google Shopping were to end up in Le Monde's Google Memorial, le petit musée des projets Google abandonnés? Without any of its other businesses, most of which don't advertise at all, Google would still have around 90% of the US search market.
The idea that platforms can't sell through their own market isn't a way of preventing Google being a monopoly, although it might be a way to address just one of the bad effects of their monopoly. I agree, for example, that Amazon's own-label predation of its vendors is an activity worth suppressing via anti-trust, I doubt that Amazon-branded products are a big enough part of Amazon's business that eliminating them would dent its monopoly.
Of course, forbidding Google from linking to content on its own Web properties in its search results would be conceivable, but would raise both serious 1st Amendment issues and massive public opposition. It would, for example, make blogs such as this one, and YouTube videos, invisible to the dominant search engine.
Regulating Google?
The EU has been attempting to address tech platform monopolies by regulation. It seems fair to say that, other than cost-of-doing-business fines, their attempts have run into unintended consequences:-
The EU tried to address Google's dominance in browser search on Android directly by mandating that, during installation, the browser user had to select among a set of alternative search engines. Google gamed that idea, as Paul Sawers reports in Google’s rivals opt out of search engine auction, calling it ‘unethical’ and ‘anti-competitive’:
So Google responded to being forced to change by turning the change into a profit center. And how many Android users chose a non-Google option?
Google announced in early August that it planned to hold an auction to allow alternative search engines to become the default providers on mobile devices in Europe. Starting in 2020, everyone who sets up a new Android device, or factory resets their existing device, will see a choice screen asking them to select which search engine they wish to use as a default.
Source
Search providers are required to apply for inclusion through a bidding process to become one of three alternative choices to Google Search.
The move was in response to a record $5 billion fine issued last year by EU antitrust regulators for the way it bundled its services on Android, effectively forcing phone manufacturers to preinstall certain Google apps to gain access to others. In response ... earlier this year Google started suggesting alternative browser and search engines for Android users, though Chrome and Google Search were still enabled as default. -
The EU tried to address the platform's "surveillance capitalism" business model with the GDPR. This turns out to have interesting capabilities, as Iain Thomson reports in Talk about unintended consequences: GDPR is an identity thief's dream ticket to Europeans' data:
When Europe introduced the General Data Protection Regulation (GDPR) it was supposed to be a major step forward in data safety, but sloppy implementation and a little social engineering can make it heaven for identity thieves.
Before laws such as the GDPR and DMCA are finalized they need to be "Red Teamed" to answer the question "what could possibly go wrong?"
In a presentation at the Black Hat security conference in Las Vegas James Pavur, a PhD student at Oxford University who usually specialises in satellite hacking, explained how he was able to game the GDPR system to get all kinds of useful information on his fiancée, including credit card and social security numbers, passwords, and even her mother's maiden name. - The EU's complete surrender to the copyright lobby in Article 13/17 would have the effect of cementing the existing platform's dominance by making it impossibly expensive and risky to start up a competitor. To avoid liability, the competitor would need "upload filters" that only the dominant platforms could afford.

Are the ideas being floated for new regulations in the US any better?
The New Tech Watchdog that "would be able to move faster and have the expertise to constantly track the tech markets and trends" could only have an impact if the DoJ or the FTC accepted their advice; it wouldn't have any enforcement powers of its own. But absent major change in the political context they wouldn't get any resources and the enforcers would ignore them. If there were to be a sea change in the political context, part of the result would presumably provide the resources and expertise the DoJ and the FTC would need to do the job themselves.
I'm pretty skeptical that efforts to Unlock the Data would have much effect on their own. As I wrote in It Isn't About The Technology:
Note that, commendably, Google has for many years allowed users to download the data they create in the various Google systems (but not the data Google collects about them) via the Data Liberation Front, now Google TakeOut. It hasn't caused their users to leave.Where would they go? Note the distinction between the data users create (Type 1) and the data Google collects about them (Type 2). Google (like the other platforms) believes that Type 2 data is the holy grail of their business, because it enables targeted advertising. Advertisers pay a lot more for targeted ads than for "contextual" ads such as search keywords.
But there is a lot of evidence that advertisers are being ripped off. Here is more from It Isn't About The Technology:
Natasha Lomas' The case against behavioral advertising is stacking up ..., based on research by Carnegie Mellon University professor of IT and public policy, Alessandro Acquisti, which showed that:There is more recent evidence in Timothy B. Lee's Why some experts are skeptical of Google’s new Web privacy strategy:
behaviourally targeted advertising had increased the publisher’s revenue but only marginally. At the same time they found that marketers were having to pay orders of magnitude more to buy these targeted ads, despite the minuscule additional revenue they generated for the publisher.The alternative to targeted ads is DuckDuckGo-style contextual ads. Lomas continues:
“What we found was that, yes, advertising with cookies — so targeted advertising — did increase revenues — but by a tiny amount. Four per cent. In absolute terms the increase in revenues was $0.000008 per advertisment,” Acquisti told the hearing. “Simultaneously we were running a study, as merchants, buying ads with a different degree of targeting. And we found that for the merchants sometimes buying targeted ads over untargeted ads can be 500% times as expensive.”
If Acquisti’s research is to be believed ... there’s little reason to think [contextual] ads would be substantially less effective than the vampiric microtargeted variant that Facebook founder Mark Zuckerberg likes to describe as “relevant”.Given Facebook's history of lying about metrics, even if it did produce internal data showing that the targeted ads were worth the cost, why should advertisers believe it? And if the internal data doesn't show that, Facebook can't afford to release it.
The ‘relevant ads’ badge is of course a self-serving concept which Facebook uses to justify creeping on users while also pushing the notion that its people-tracking business inherently generates major extra value for advertisers. But does it really do that? Or are advertisers buying into another puffed up fake?
Facebook isn’t providing access to internal data that could be used to quantify whether its targeted ads are really worth all the extra conjoined cost and risk. While the company’s habit of buying masses of additional data on users, via brokers and other third party sources, makes for a rather strange qualification. Suggesting things aren’t quite what you might imagine behind Zuckerberg’s drawn curtain.
Google's post was blasted by a pair of Princeton computer scientists who have long advocated for stricter browser privacy protections. ...DuckDuckGo has a sustainable business model based on advertising that doesn't involve tracking or collecting information on users:
The researchers disputed Google's claim that nuking tracking cookies would undermine the economic foundation of the online advertising industry. They point out that after the EU adopted the General Data Protection Regulation, the New York Times discontinued its use of tracking cookies in Europe. The Grey Lady shifted to using contextual and geographic ad targeting—and its ad revenue hasn't suffered as a result.
"This keyword-based advertising is our primary business model. When you search on DuckDuckGo, we can show you an ad based on the keywords you type in. That’s it. And it works. Our privacy policy, in a nutshell, is to not collect or share any personal information at all. Every time you search on DuckDuckGo it is as if you were there for the first time – anonymous."So there is a viable competitor that doesn't even need access to Google's data, but their market share in US search is only 0.4%.
Adversarial Interoperability For Google?
Roger McNamee points out that, even if sharing were forced upon Facebook, it would likely do little to reduce their market power:consumers, not the platforms, should own their own data. In the case of Facebook, this includes posts, friends, and events—in short, the entire social graph. Users created this data, so they should have the right to export it to other social networks. Given inertia and the convenience of Facebook, I wouldn’t expect this reform to trigger a mass flight of users. Instead, the likely outcome would be an explosion of innovation and entrepreneurship. Facebook is so powerful that most new entrants would avoid head-on competition in favor of creating sustainable differentiation. Start-ups and established players would build new products that incorporate people’s existing social graphs, forcing Facebook to compete again.After all, allowing users to export their data from Facebook doesn't prevent Facebook maintaining a copy.
Cory Doctorow has long been arguing that Big Tech's problem is Big, not Tech. His recent series of posts at EFF's Deeplinks has argued in favor of "Adversarial Interoperability", the idea that platforms should be required not simply to allow individuals to export their data, but to export APIs that allow other services to exploit the data that they hold:
- In SAMBA versus SMB: Adversarial Interoperability is Judo for Network Effects he uses Andrew Tridgell's reverse-engineering of Microsoft's SMB protocol as an early example:
SAMBA was created by using a "packet sniffer" to ingest raw SMB packets as they traversed a local network; these intercepted packets gave Tridgell the insight he needed to reverse-engineer Microsoft's proprietary networking protocol.
Tridgell didn't need Microsoft's permission to implement interoperation, nor to release the result as open source[2]. The ability SAMBA provided for Microsoft machines to interoperate with others increased Microsoft's bottom line; a smaller share of a bigger market. - In 'IBM PC Compatible': How Adversarial Interoperability Saved PCs From Monopolization:
As IBM's PC became the standard, rival hardware manufacturers realized that they would have to create systems that were compatible with IBM's systems. The software vendors were tired of supporting a lot of idiosyncratic hardware configurations, and IT managers didn't want to have to juggle multiple versions of the software they relied on. Unless non-IBM PCs could run software optimized for IBM's systems, the market for those systems would dwindle and wither.
He describes how Tom Jennings and a "clean-room" team at Phoenix Technologies made this possible by developing a compatible ROM. IBM ended up with a major slice of a much bigger market than they would have had if they had tried to suppress "PC-compatible" machines. - In Interoperability and Privacy: Squaring the Circle he discusses ways of applying the concept to Facebook:
Facebook users are eager for alternatives to the service, but are held back by the fact that the people they want to talk with are all locked within the company's walled garden. Interoperability presents a means for people to remain partially on Facebook, but while using third-party tools that are designed to respond to their idiosyncratic needs. While it seems likely that no one is able to build a single system that protects 2.3 billion users, it's certainly possible to build a service whose social norms and technological rules are suited to smaller groups. Facebook can't figure out how to serve every individual and community's needs--but those individuals and communities might be able to do so for themselves, especially if they get to choose which toolsmith's tools they use to mediate their Facebook experience.
See Microsoft's "embrace and extend" approach to standards. If effective interoperability could be imposed upon Facebook Doctorow believes it would significantly improve competition:
Even if we do manage to impose interoperability on Facebook in ways that allow for meaningful competition, in the absence of robust anti-monopoly rules, the ecosystem that grows up around that new standard is likely to view everything that's not a standard interoperable component as a competitive advantage, something that no competitor should be allowed to make incursions upon, on pain of a lawsuit for violating terms of service or infringing a patent or reverse-engineering a copyright lock or even more nebulous claims like "tortious interference with contract."
Facebook is viewed as holding all the cards because it has corralled everyone who might join a new service within its walled garden. But legal reforms to safeguard the right to adversarial interoperability would turn this on its head: Facebook would be the place that had conveniently organized all the people whom you might tempt to leave Facebook, and even supply you with the tools you need to target those people.
Although I believe that interoperability with Facebook would be a good thing, spawning considerable creativity in social media technology, I share McNamee's skepticism that it would dent Facebook's dominance. If only because Facebook would buy up or clone the good ideas. - In A Cycle of Renewal, Broken: How Big Tech and Big Media Abuse Copyright Law to Slay Competition he uses the Betamax case as an example of the evolution of technology, with cable going from trying to kill VCRs to offering DVRs to their customers:
It's easy to imagine that this is the general cycle of technology: a new technology comes along and rudely shoulders its way into the marketplace, pouring the old wine of the old guard into its shiny new bottles. The old guard insist that these brash newcomers are mere criminals, and demand justice.
The reason it doesn't work any more is the extraordinary power Section 1201 of the DMCA gives incumbents to prevent "adversarial interoperability":
The public flocks to the new technology, and, before you know it, the old guard and the newcomers are toasting one another at banquets and getting ready to sue the next vulgarian who has the temerity to enter their market and pour their old wine into even newer bottles.
That's how it used to work, but the cycle has been interrupted.The statute does not make an exemption for people who need to bypass a copyright lock to do something legal, so traditional acts of "adversarial interoperability" (making a new thing that plugs into an old thing without asking for permission) can be headed off before they even get started. Once a company adds a digital lock to its products, it can scare away other companies that want to give it the broadcasters vs records/cable vs broadcasters/VCRs vs cable treatment. These challengers will have to overcome their fear that "trafficking” in a “circumvention device" could trigger DMCA 1201's civil damages or even criminal penalties—$500,000 and 5 years in prison...for a first offense.
The somewhat strange design of the LOCKSS technology is an example of the effect of Section 1201. To avoid Section 1201 liability for us the developers the system had to ensure each library had specific permission from each individual publisher to preserve its copy of the copyright academic journals to which it subscribed.
Adversarial interoperability is clearly a good thing, even in most cases for the dominant market player, as the Intel and Microsoft examples show. What would it mean in the context of Google's monopoly of US search?
To over-simplify an extremely complex eco-system, there are three ways to inter-operate with Google as a search engine:
- Searchers, who query it to find information. They submit their query via a public Web service API, but the result comes back as complex HTML which is difficult for a programmatic front-end to interpret. Google can deliver the result as JSON or XML not HTML (cf. Yahoo's BOSS API), but makes this capability available only to Google Site Search customers. The reason is that it makes ad-blocking trivial, so implementing "adversarial interoperability" by requiring structured data results would kill Google's business model.
- Search Engine Optimizers, who work with publishers to get their content ranked highly in Google searches. They're already in an adversarial relationship with Google, and it wouldn't be in either Google's or the public interest to tip the relationship further against Google.
- Advertisers, who pay Google to feature their content in the pages searchers see. Since they have money, unlike SEOs and searchers, it is their interests in a level playing field for ad auctions that the anti-trust efforts focus on. "Adversarial interoperability" in this context would look like Wall Street, with multiple interconnected marketplaces "cooperating to provide price discovery". The example of Wall Street isn't encouraging.
Is A Google Search Monopoly Bad?
If we can't think of a way to reduce Google's dominance of the US Web search market, we're going to have to live with it. How bad would that be?K. Sabeel Rahman's The New Octopus lays out one of the ways it would be bad:
A second type of power arises from what we might think of as a gatekeeping power. Here, the issue is not necessarily that the firm controls the entire infrastructure of transmission, but rather that the firm controls the gateway to an otherwise decentralized and diffuse landscape.The State AGs obviously think living with it would be bad, based on a different set of incentives. In Nearly Every State Is Launching An Antitrust Investigation Of Google Nicole Nguyen writes:
This is one way to understand the Facebook News Feed, or Google Search. Google Search does not literally own and control the entire internet. But it is increasingly true that for most users, access to the internet is mediated through the gateway of Google Search or YouTube’s suggested videos. By controlling the point of entry, Google exercises outsized influence on the kinds of information and commerce that users can ultimately access—a form of control without complete ownership.
Crucially, gatekeeping power subordinates two kinds of users on either end of the “gate.” Content producers fear hidden or arbitrary changes to the algorithms for Google Search or the Facebook News Feed, whose mechanics can make the difference between the survival and destruction of media content producers. Meanwhile, end users unwittingly face an informational environment that is increasingly the product of these algorithms—which are optimized not to provide accuracy but to maximize user attention spent on the site. The result is a built-in incentive for platforms like Facebook or YouTube to feed users more content that confirms preexisting biases and provide more sensational versions of those biases, exacerbating the fragmentation of the public sphere into different “filter bubbles.”
These platforms’ gatekeeping decisions have huge social and political consequences. While the United States is only now grappling with concerns about online speech and the problems of polarization, radicalization, and misinformation, studies confirm that subtle changes—how Google ranks search results for candidates prior to an election, for instance, or the ways in which Facebook suggests to some users rather than others that they vote on Election Day—can produce significant changes in voting behavior, large enough to swing many elections.
"When my daughter is sick and I search online for advice, I want the best advice from the best doctors, not the ones who can spend the most on advertising," the Republican attorney general of Arkansas, Leslie Rutledge, said during a press conference held on the steps of the Supreme Court.
 |
| Google results page |
The image shows the results for a search I did that advertisers would think worth bidding for in the keyword auction. The top 4 results are all paid content, the winners in the keyword auction for "london hotel". Next comes a big chunk of Google's own content, effectively an ad for their travel service. Even on my relatively large desktop screen I can't see any organic results without scrolling down. So unless you scroll down, Google is a paid-search engine.
In It Isn't About The Technology I included Chuck McManis' explanation for the absence of organic search results:
What Chuck describes is a conflict of interest that is fundamental to any advertising-funded search engine. They would rather show you ads than search results. A second-order effect is that they would rather show you results that advertisers want to buy ads near, than "organic" results that actually answer your question.publications, as recently as the early 21st century, had a very strict wall between editorial and advertising. It compromises the integrity of journalism if the editorial staff can be driven by the advertisers. And Google exploited that tension and turned it into a business model.How did they do that?
When people started using Google as an 'answer this question' machine, and then Google created a mechanism to show your [paid] answer first, the stage was set for what has become a gross perversion of 'reference' information.Why would they do that? Their margins were under pressure:
The average price per click (CPC) of advertisements on Google sites has gone down for every year, and nearly every quarter, since 2009. At the same time Microsoft's Bing search engine CPCs have gone up. As the advantage of Google's search index is eroded by time and investment, primarily by Microsoft, advertisers have been shifting budget to be more of a blend between the two companies. The trend suggests that at some point in the not to distant future advertising margins for both engines will be equivalent.And their other businesses weren't profitable:
Google has scrambled to find an adjacent market, one that could not only generate enough revenue to pay for the infrastructure but also to generate a net income . Youtube, its biggest success outside of search, and the closest thing they have, has yet to do that after literally a decade of investment and effort.So what did they do?
As a result Google has turned to the only tools it has that work, it has reduced payments to its 'affiliate' sites (AdSense for content payments), then boosted the number of ad 'slots' on Google sites, and finally paying third parties to send search traffic preferentially to Google (this too hurts Google's overall search margin)And the effect on users is:
On the search page, Google's bread and butter so to speak, for a 'highly contested' search (that is what search engine marketeers call a search query that can generate lucrative ad clicks) such as 'best credit card' or 'lowest home mortgage', there are many web browser window configurations that show few, if any organic search engine results at all!In other words, for searches that are profitable, Google has moved all the results it thinks are relevant off the first page and replaced them with results that people have paid to put there. Which is pretty much the definition of "evil" in the famous "don't be evil" slogan notoriously dropped in 2015. I'm pretty sure that no-one at executive level in Google thought that building a paid-search engine was a good idea, but the internal logic of the "slow AI" they built forced them into doing just that.
In the screenshot above I included the developer tools panel, so you can see that all the content on the results page came from Google. There aren't any third-party ads such as you would see on a publisher page, served by the advertiser or an ad insertion service. Google doesn't want them, because they would leak information to advertisers that Google wants to keep for itself.
 |
| Source |
Do a Google search for Basecamp, a web-based project management tool company, and you might see one or more ads for competitors show up in results above the actual company.Skewing content to match advertisers preferences is becoming a serious problem for sites in general, but in particular for news sites. Yves Smith writes in Advertisers Blacklisting News, Other Stories with “Controversial” Words Like “Trump”, quoting a Wall Street Journal story::
Basecamp CEO and co-founder Jason Fried sounded off against the practice Tuesday, calling it a "shakedown" and saying it's like ransom to have to pay up just to be seen in results.
"When Google puts 4 paid ads ahead of the first organic result for your own brand name, you're forced to pay up if you want to be found," he tweeted Tuesday afternoon. "It's a shakedown. It's ransom. But at least we can have fun with it. Search for Basecamp and you may see this attached ad."
The tweet includes the screenshot of an ad for Basecamp, reading "Basecamp.com | We don't want to run this ad." The copy says "We're the #1 result, but this site lets companies advertise against us using our brand. So here we are. A small, independent co. forced to pay ransom to a giant tech company."
Integral Ad Science Inc., a firm that ensures ads run in content deemed safe for advertisers, said that of the 2,637 advertisers running campaigns with it in June, 1,085 brands blocked the word “shooting,” 314 blocked “ISIS” and 207 blocked “Russia.” Almost 560 advertisers blocked “Trump,” while 83 blocked “Obama.”Smith writes:
The average number of keywords the company’s advertisers were blocking in the first quarter was 261. One advertiser blocked 1,553 words, it said.
...
CNN.com said it is testing a new product dubbed SAM, for Sentiment Analysis Moderator, that uses machine learning to score its site’s content for whether it will make readers feel “mostly negative,” “somewhat negative,” “neutral,” “somewhat positive” or “mostly positive.”…
The New York Times and USA Today also have been using sentiment analysis to help brands advertise in news articles that may have a positive or optimistic sentiment.
But you can see where this is going. News will have to be massaged to have a high enough “feel good” quotient. How soon will we see AI-based editing that will flag negative-sounding content and send it back to the author for a rewrite?So we can make the following statements:
And what does it say about the US as a society that we tolerate only positive emotions? Every major religion is based on the inevitability of suffering. Trying to deny that that is fundamental to the human condition is a fast track to neurosis.
- Search is essential to the usefulness of the Web, and thus the Internet.
- US Web search is dominated by a single search engine, and there is no realistic prospect of displacing it.
- The dominant search engine is funded by advertising, which involves a fundamental conflict of interest; the results users see are not the best answers to their query but those that are most profitable for the search engine.
- The most profitable searches reflect the interests of the wealthiest companies (and of the politicians they fund). Accurate information about "controversial" issues, such as climate change, becomes hard to find.
My Proposal
Part of the problem is that the discussion ignores the other monopolists in the room, the ISP oligopoly. This isn't an accident. In Much Of The Assault On 'Big Tech' Is Being Driven By 'Big Telecom', Karl Bode writes:It's routinely understated how telecom lobbying, not a sincere worry about market power or privacy, is what's driving much of this current policy paradigm in DC (including much of the hyperventilation over nonexistent Censorship of Conservatives). The telecom sector is pushing hard into an online advertising sector traditionally dominated by Silicon Valley. As such, telecom lobbyists have spent several years now pushing to hamstring their direct competitors with the help of cash-compromised lawmakers and full blown regulatory capture.What we need is an anti-trust ruling that says, for example, no search engine with more than 10% market share of US Web search may run any kind of "for pay" content in its result pages, because to do so is a conflict of interest. In other words, no paid-search engine may have more than 10% market share. Think of this as requiring large search engines to re-instate the wall between editorial and advertising.
That includes successfully convincing government that a sector filled with natural, historically-predatory monopolies should see no guard rails whatsoever (see the killing of net neutrality and the neutering of the FCC as example A). Yet somehow, there are still a lot of folks in tech policy circles who see the lopsided focus on "big tech" as entirely authentic, and any failure to police telecom as somehow coincidental.
This would raise two issues:
- As we see from their willingness to throw money at "moonshots" such as Waymo, and cash sinks such as YouTube, running a good Web search engine doesn't take much of Google's revenue. But it isn't free; someone has to pay for it. The obvious place to get the money is from a tax on ISPs, who wouldn't have a business without a Web search engine. Since the search engine would not be running ads against the results, there would be no reason not to deliver them in XML, enabling "adversarial interoperability" with the search engine.
- I, like most Web users, use ad-blockers because I hate ads. But I must admit that companies need a place to advertise their wares. If they can't buy ads on the search engine, where can they advertise? On the sites that the search results link to! This would help solve the problem of the "death of news"; news and other websites becoming uneconomic because the advertisers have migrated to Google (and Facebook, which is why the ruling should also state that any social media site with more than 10% market share is forbidden to run any "for-pay" content).
As a Londoner who emigrated to the US in the 80s, I lived through the heyday of the advertisement-free BBC, funded by a "license fee" (i.e. a tax on users of TV sets). I'm obviously nostalgic for those days, and its clear that the BBC model failed under the stress of technological change. But I do think there is value in looking at Web search, and possibly social media, as regulated public utilities once they achieve dominance in their market.
Footnotes
-
The link goes to Alec Nevala-Lee's discussion of Noise Level, a novelette published in Astounding #18, December 1952. I read it a few years later in a SF anthology borrowed from the Barnet Public Library, and it has stuck with me ever since. The story was pitched by John W. Campbell, the legendary (but see this) SF editor to Robert Heinlein, who turned it down, then written by Raymond F. Jones. It describes a technique for creating technological breakthroughs to order, in this case an anti-gravity machine. Nevala-Lee traces the idea to Norbert Wiener, who wrote:
Source
“When we consider a problem of nature such as that of atomic reactions and atomic explosives, the largest single item of information which we can make public is that they exist. Once a scientist attacks a problem which he knows to have an answer, his entire attitude is changed.” I can’t prove it, but I’m pretty sure that this sentence gave Campbell the premise that was later written up by Raymond F. Jones as “Noise Level.”
The story was anthologized, see this WorldCat search. which enabled me to borrow the 1955 anthology Stories for Tomorrow from the Stanford Library and re-read it after six decades.
- I had a related experience nearly a decade earlier than Tridgell's work on SAMBA. I helped with the design of the Andrew File System (AFS) at CMU by a team under John Howard (Andrew: A distributed personal computing environment, 1986) while Russel Sandberg, Bob Lyon, Bill Joy, Steve Kleiman, David Goldberg and others at Sun worked on the Network File System (NFS) (Design and Implementation of the Sun Network File System, 1985).
Both are still in use a third of a century later, but it is clear that NFS had the bigger impact. It is important to note that both were developed before the current understanding of "open source" emerged with the GPL (1989) and the resolution of AT&T's lawsuit against BSDI and the University of California (1994). AFS was a complex, licensed software package that required central IT to run servers and clients to install software. NFS was a published network protocol that competitors could easily implement as part of their OS, after which individual workstations could run it or not as they chose. In 1989, as version 2 was being developed, Bill Nowicki published the version 1 protocol as RFC1094. Sun actively promoted NFS, holding "connectathons" at which everyone's implementation was tested against everyone else's. NFS' easy connectivity in heterogeneous environments was vital to Sun's growth, another illustration of the benefits of "adversarial interoperability". Note again that the winner was a network protocol.

{kind=link}
{kind=link}
20 comments:
Clearly, the FAANGs have real anti-trust problems. But equally clearly, some of the "techlash" is being ginned up by the oligopoly telcos and other competitors. Some of this is above-board lobbying, but some is astroturfing. Kate Cox's “Grassroots” anti-Amazon nonprofit turns out to be retailer astroturfing reports:
"It's no secret that retailers who compete with Amazon for consumer dollars want regulators to take a closer look at the way their titanic, globe-spanning rival works. They've openly said so, many times. And yet, three major firms reportedly spent a great deal of time and effort obscuring their ties to a nonprofit that exists to rally support against Amazon.
The nonprofit, called the Free and Fair Markets Initiative, describes itself as "a nonprofit watchdog committed to scrutinizing Amazon’s harmful practices and promoting a fair, modern marketplace that works for all Americans." According to a new report today from The Wall Street Journal, however, the group is funded by rivals, including Walmart, Oracle, and mall-owner Simon, who all have a strong financial interest in dethroning Amazon."
Mark Coatney, a former director of Tumblr, has a New York Times op-ed arguing that We Need a PBS for Social Media. His argument about Facebook and other social media platforms matches mine about Google in search, that there are fundamental conflicts of interest in advertiser-funded platforms and breakups don't address them. The solution is platforms without ads, funded by tax dollars. Coatney's op-ed is a must-read.
More on the lobbying from the telcos pushing anti-trust investigations of the FAANGs from Karl Bode in Comcast Apparently Feels Qualified To Give Google Lectures On Monopoly Power:
"Yes, countless experts have noted for a decade than US antitrust enforcement has grown toothless and frail, and our definitions of monopoly power need updating in the Amazon era. Facebook's repeated face plants on privacy (and basic transparency and integrity) have only added fuel to the fire amidst calls to regulate "big tech." That said, if we're looking for expert insight into the genuine problems posed by "big tech," maybe skip taking advice from natural telecom monopolies whose only real motivation here is to elbow in on Silicon Valley advertising revenues while saddling competitors with layers of new regulation."
Cory Doctorow has collected links to, and brief summaries of, his recent writing on Adversarial Interoperability. It is a valuable resource.
In If You Think Google Is Too Dominant And Needs More Competition... You Should Actually Support Its Petition Concerning API Copyrights, Mike Masnick points out that if Oracle succeeds in its effort to subject APIs to copyright "adversarial interoperability" will become even less possible than it is now.
What could possibly go wrong? In How Amazon.com moved into the business of U.S. elections, Nadita Bose reports that:
"Amazon.com Inc’s cloud computing arm is making an aggressive push into one of the most sensitive technology sectors: U.S. elections.
The expansion by Amazon Web Services into state and local elections has quietly gathered pace since the 2016 U.S. presidential vote. More than 40 states now use one or more of Amazon’s election offerings, according to a presentation given by an Amazon executive this year and seen by Reuters.
So do America’s two main political parties, the Democratic presidential candidate Joe Biden and the U.S. federal body charged with administering and enforcing federal campaign finance laws.
While it does not handle voting on election day, AWS - along with a broad network of partners - now runs state and county election websites, stores voter registration rolls and ballot data, facilitates overseas voting by military personnel and helps provide live election-night results, according to company documents and interviews."
What could possibly go wrong? In Meet America’s newest military giant: Amazon Sharon Weinberger reports that:
"The Pentagon’s controversial $10bn JEDI cloud computing deal is one of the most lucrative defense contracts ever. Amazon’s in pole position to win—and its move into the military has been a long time coming."
"New York State Attorney General Letitia James announced Tuesday that 47 attorneys general from states and U.S. territories plan to take part in a New York-led antitrust probe into Facebook. Shares of Facebook fell 3.2% on the news.
The multistate investigation was announced in September with participation from seven other states, but it has since expanded to nearly the entire country. The probe will zero in on whether Facebook broke any state or federal laws as a result of any anti-competitive conduct related to its dominance of social media."
From 47 attorneys general are investigating Facebook for antitrust violations by Annie Palmer
Barry Ritholtz reports on Stacy Mitchell's Walmart’s Monopolization of Local Grocery Markets who writes:
"In 43 metropolitan areas and 160 smaller markets, Walmart captures 50 percent or more of grocery sales, our analysis of 2018 spending data found. In 38 of these regions, Walmart’s share of the grocery market is 70 percent or more. Our findings provide a stark illustration of the failings of contemporary antitrust policy. They also show that more will be required to fix our broken markets than reforms to merger policy."
Ritholtz comments:
"The entire report is worth perusing, but what is so intriguing is how the analytics were able to identify the strength or weakness of the local land use regulations to reach its conclusion. Add to that Supreme Court decisions which undercut Anti-Trust enforcements, and you get a retail giant — and little or no competition."
Karl Bode's This Idaho Town Lets You Switch Between Cheap Fiber ISPs In A Matter Of Seconds shows the problms caused by the ISP monopolies:
"Back in 2016, the city of Ammon, Idaho (population 16,500) decided to build an open access broadband network that let multiple private ISPs offer service to customers over city-owned fiber. The resulting competition has, several years later, resulted in (surprise), better, faster, and cheaper access to broadband. As a result, this city in Idaho now boasts better broadband infrastructure than most US "tech hubs" like San Francisco and Seattle, both of which have flirted with the idea but never followed through"
Kierne McCarthy's Top American watchdog refuses to release infamous 2012 dossier into Google’s anti-competitive behavior reports that:
"The Federal Trade Commission (FTC) has refused to release an infamous report into Google’s anti-competitive behavior, claiming that staff reports are exempt from America's Freedom of Information Act.
"Unfortunately, we are not able to honor your request," FTC chair Joe Simons wrote to Senator Josh Hawley (R-MO) this week following Hawley’s request last month for the full report to be released in the public interest."
And:
"The 2012 report found that Google had caused “real harm” to the search and ads market and, among other things, Google execs had rigged its own search results to favor its own services and products over competitors. The report even cited internal Google documents in which execs at the tech giant seemingly admitted that they had written code to “bias ourselves.”
Despite those findings, and an FTC staff recommendation that the regulator bring a lawsuit against Google, the report was not acted on and its contents only became known when part of it was accidentally released in a record request three years later in 2015."
Also in Google news today is McCarthy's Google forks out $2.1bn for Fitbit – and promises not to exploit all that delicious health data to sling ads (honest):
"Google’s efforts to repeat its approach to the mobile phone market with WearOS took a hit last year when Huawei ditched it in favor of its own home-grown operating system. Google clearly decided it needed to control some hardware in the market and so guarantee a foothold - and a $2bn acquisition of Fitbit was the answer.
...
Fitbit users can expect the information from their smart-watches, including location, activity, heart rate, as well as any additional information on things like nutrition, weight, and so on that they input in order to receive recommendations, to be connected to other personal data that Google may hold on them.
That can encompasses everything from your emails (Gmail) to your search results (Google), web activity (Chrome), home activity (Nest) to your location and frequently used apps (Android phones). All that data will then be packaged in 100 different ways and sold to advertisers looking to target specific individuals."
Jeff Henriksen's Antitrust and the intrinsic value of Alphabet is a fascinating look at Google's domination of the advertising infrastructure that comes to a similar conclusion to mine:
"Regulators would also have to face the very real possibility that a break-up of Google might accomplish little in terms of its market dominance. Even if the company was broken up into multiple parts, the individual entities would still be dominant in size relative to their independent peers. Google would still dominate search; YouTube would still dominate free online video; AdSense would still be the largest ad server for small publishers; AdMob would still dominate mobile ad serving for Android apps; Google Ad Manager would still be the go-to ad server for premium/enterprise-level publishers; and, based on its current market share according to mainstream thinking, Display and Video 360 would remain one of the largest DSPs."
Go read the whole thing.
Cory Doctorow makes a good point in Bill Gates just accidentally proved that even "unsuccessful" antitrust enforcement works:
"In a speech at the Dealbook conference, Gates says that Microsoft wasn't able to use Windows Mobile to destroy Android because the Microsoft was "distracted" by the antitrust action.
It's easy to think that Gates is saying that the company's lawyers and engineers were too busy replying to snoopy DoJ and FTC enforcers to put in the hours to make Windows Mobile a success, but Android launched in 2008, seven years after Microsoft settled its antitrust claims.
When Gates says the company was "distracted," what he means is that, seven years after the nine-year antitrust enforcement action, the company was still too traumatized and gunshy to deploy the kinds of tactics that once gave it 95% of the desktop computing market."
In If a monopoly gives away free services is it a problem?, Izabella Kaminska explores an important question and concludes:
"In other words forcing the likes of Google to pay consumers for their search activity could, in the worst-case scenario, make it unsustainable to provide those services altogether.
That’s not to say their power shouldn’t be challenged, but given the modern economy’s dependence on search engines, the consequences of such actions must be kept in mind. It could just be that the only viable alternative provider would have to become the government."
It is a must-read piece.
Prime Leverage: How Amazon Wields Power in the Technology World by Daisuke Wakabayashi details AWS' anti-competitive behavior in software:
"smaller rivals say they have little choice but to work with Amazon. Given the company’s broad reach with customers, start-ups often agree to its restrictions on promoting their own products and voluntarily share client and product information with it. For the privilege of selling through A.W.S., the start-ups pay a cut of their sales back to Amazon.
Some of the companies have a phrase for what Amazon is doing: strip-mining software. By lifting other people’s innovations, trying to poach their engineers and profiting off what they made, Amazon is choking off the growth of would-be competitors and forcing them to reorient how they do business, the companies said."
There's a saying that "a conservative is a liberal who has been mugged". But, as the The American Conservative is coming to realize, "a liberal is a conservative who has flown in economy". The headline is How Airlines Exploit Laws to Literally Squeeze Customers and the subhead is "Vanishing competition and lax oversight are leading to higher ticket prices, shoddy service, and cramped spaces." So much for the ideology of deregulation!
Karen Weise's Prime Power: How Amazon Squeezes the Businesses Behind Its Store is a must-read deep dive into the rapidly rising levels of dissatisfaction among Amazon's less visible customers, the suppliers of its cornucopia of goods:
"Amazon punishes the businesses if their items are available for even a penny less elsewhere. It pushes them to use the company’s warehouses. And it compels them to buy ads on the site to make sure people see their products.
All of that leaves the suppliers more dependent on Amazon, by far the nation’s top online retailer, and scrambling to deal with its whims. For many, Amazon eats into their profits, making it harder to develop new products. Some worry if they can even survive."
Benedict Evas' How to lose a monopoly: Microsoft, IBM and anti-trust makes an excellent point:
"IBM ruled mainframes and Microsoft ruled PCs, and when those things were the centre of tech, that gave them dominance of the broader tech industry. When the focus of tech moved away from mainframes and then PCs, IBM and then Microsoft lost that dominance, but that didn’t mean they stopped being big companies. We just stopped being scared of them.
For both IBM and Microsoft, market power in one generation of tech didn’t give them market power in the next, and anti-trust intervention didn’t have much to do with it. It doesn’t matter how big your castle is if the trade routes move somewhere else."
Go read the whole post.
Matt Stoller's This is Not a Democracy, It's a Cheerocracy: The Cheerleading Monopoly Varsity Brands is a fascinating dissection of Bain Capital's monopoly over the "sport" of cheerleading:
"So there we have it all. Catastrophic injuries, rigged competitions, vertical foreclosure, private equity. Fixing this situation isn’t that hard, and basically requires a restoration of basic anti-monopoly principles, with glitter. That means stopping coercive rebates, ending long-term gym contracts, having competitions not controlled by Varsity, and regulating cheerleading like a sport."
In In 2020, Two Thirds of Google Searches Ended Without a Click
Rand Fishkin reports that Google's monopoly on seacrh keeps growing:
"From January to December, 2020, 64.82% of searches on Google (desktop and mobile combined) ended in the search results without clicking to another web property. That number is likely undercounting some mobile and nearly all voice searches, and thus it’s probable that more than 2/3rds of all Google searches are what I’ve been calling “zero-click searches.”
...
Google’s efforts at a mobile-first search experience have paid immense dividends, answering a staggering 3/4ths of all mobile search queries without a click."
Post a Comment