Over the seventeen and a half years that we have been working on the LOCKSS technology it has evolved considerably. This talk will cover two aspects of its recent evolution:
- First, recently completed work funded by the Mellon Foundation to enhance the system's capabilities while preserving its architecture.
- Second, work under way now to transform the system's architecture while preserving its capabilities.
Functionality
Although the initial development of the LOCKSS technology was funded by NSF, the Mellon Foundation and Sun Microsystems, grants are not a viable basis for a production digital preservation system. For more than a decade, the LOCKSS team's business model has been "Red Hat", free, open-source software and paid support. From 2007 to 2012 we operated in the black with no grant funds whatsoever.Experience with operating the "Red Hat" model has been generally positive. It requires a development process yielding frequent small enhancements to the system that meet the evolving needs of the user community, and a consistent focus on reducing the costs the system imposes on both the users and the support organization.
The need for frequent small releases and reducing costs makes it difficult for the team to commit resources to infrastructure developments that, while not responding to immediate user needs, are necessary to handle foreseeable issues in the medium term. In 2012, after discussions with the Mellon Foundation about several such developments, the LOCKSS Program was awarded a grant that, over its three years, allowed for about a 10% increase in program expenditure. Detailed results were published recently in D-Lib, but here are examples in the three key areas, ingest, dissemination, and preservation.
Ingest
The two major enhancements to the ingest capabilities of the LOCKSS technology were:- First, form-filling capabilities. These allow content to be collected, for example, from many government websites, which often require a user to select from drop-down menus, push radio buttons or enter text into forms before content is obtained. My suspicion is that governments intend these techniques to make automated collection difficult.
- Second, AJAX (Asynchronous Javascript And XML) support. The Web has nearly completed its transition from a document model whose language is HTML to a programming environment whose language is Javascript. This greatly increases the difficulty of collecting content; it has to be executed not just parsed to identify the links to follow. AJAX support allows us to collect more up-to-date, dynamic web content such as, for example, the journals of the Royal Society of Chemistry.
Dissemination
The two major enhancements to the dissemination capabilities of the LOCKSS technology were:- First, implementation of the Memento (RFC7089) protocol, allowing content preserved in LOCKSS networks to be accessed via Memento-enabled browsers, and aggregated via portals such as the Time Travel Service and Ilya Kreymer's oldweb.today.
- Second, implementation of the Shibboleth authentication technology. As LOCKSS networks hold much subscription content, easier access to content had to be matched by more sophisticated access control mechanisms. Shibboleth allows access control based on a user's identity rather than their location.
Preservation
Peers in LOCKSS networks detect damage to their content, and repair it by participating in polls. The polling mechanism detects damage by discovering disagreement between instances of the same content at different peers, and enables its repair by discovering agreement. A peer that detects damage to its content requests a repair from another peer that has agreed with it about the same content in the past.This restriction is necessary because the LOCKSS system is intended to preserve valuable copyright content, such as subscription academic journals. The peer from which a repair is requested knows it is not leaking content if it remembers the requesting peer agreeing in the past about the requested content. If so, the requested peer knows it is replacing a pre-existing copy, not creating a new one.
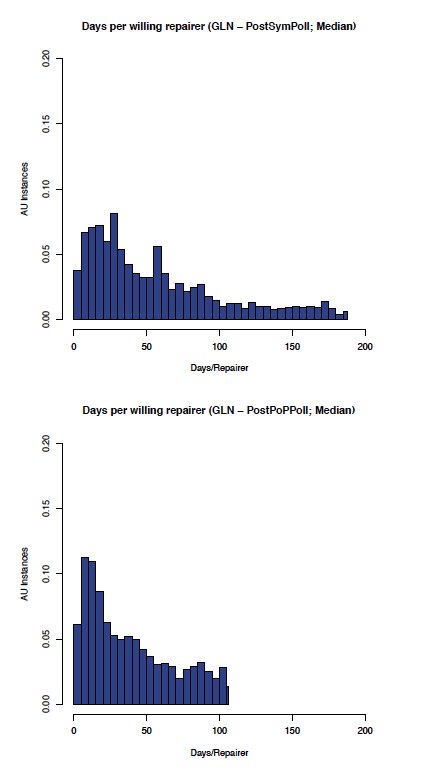
Measuring the effect of these enhancements required collecting many millions of data points. This was beyond the capacity of the existing monitoring technology, which had to be completely re-implemented. The effect of the enhancements can be seen in histograms of the delay between successive times a peer reaches new agreement on a content unit with another peer. This example shows the effect of adding proof of possession and local polls to the Global LOCKSS Network (GLN). In this case the effect was to reduce the most likely delay between new agreements from about 30 to about 10 days.
Architecture

 Amazon has been spectacularly successful at scaling its technology to match, in fact exceed, the growth of the Web. Much of the reason for this success is this famous but officially unpublished memo from Jeff Bezos in 2002. The effectiveness of this edict is explained by these pie-charts, showing that the odds of a
programming project's success decay rapidly with size. They are based on a study
of over 50,000 projects over 8 years by the Standish Group. Bezos' rules limit programming projects to a size that allows success. Both slides come from Krste Asanović's fascinating keynote at the 2014 FAST conference.
Amazon has been spectacularly successful at scaling its technology to match, in fact exceed, the growth of the Web. Much of the reason for this success is this famous but officially unpublished memo from Jeff Bezos in 2002. The effectiveness of this edict is explained by these pie-charts, showing that the odds of a
programming project's success decay rapidly with size. They are based on a study
of over 50,000 projects over 8 years by the Standish Group. Bezos' rules limit programming projects to a size that allows success. Both slides come from Krste Asanović's fascinating keynote at the 2014 FAST conference.Stanford Libraries and the Internet Archive are taking part in an IMLS-funded project to make a start on applying these rules to Web archiving technology in general by developing APIs allowing the technology to be dis-aggregated into Web services. In a related but separate effort the LOCKSS team are re-architecting the LOCKSS technology by:
- First, where possible replacing functions provided by the current monolithic LOCKSS daemon using available off-the-shelf open source software. Among these are the repository that stores preserved content, replaced by Hadoop, and the Web server that disseminates content, replaced by OpenWayback.
- Second, extracting the remaining functions from the LOCKSS daemon and encapsulating them as Web services accessed via RESTful APIs. Among the functions that will thus become available for use by other digital preservation technologies are:
- The LOCKSS polling and repair protocol.
- The technology LOCKSS uses to extract bibliographic metadata from collected content, store it in a metadata database, and support access via DOI and OpenUrl resolution.
- Improve the ability of the LOCKSS technology to scale up to meet future demands.
- Reduce costs by reducing the amount of LOCKSS-specific code the team needs to maintain.
- Enable the LOCKSS team to support Web archiving efforts at the Stanford Libraries and elsewhere by contributing code and expertise.
 We expect the APIs we develop to these services will influence the work of the IMLS API project. This diagram gives an overview of how we expect the LOCKSS system architecture to look when we are done. The whole system is open source; boxes in blue represent off-the-shelf components, and those in green LOCKSS-specific components.
We expect the APIs we develop to these services will influence the work of the IMLS API project. This diagram gives an overview of how we expect the LOCKSS system architecture to look when we are done. The whole system is open source; boxes in blue represent off-the-shelf components, and those in green LOCKSS-specific components.Deploying this set of interconnected Web services to LOCKSS systems in the field is more complex than deploying a single monolithic Java program. To mitigate this, we are using state-of-the-art "dev-ops" technology such as Docker to automate the deployment process.
The current state of this effort is that we have a Docker-ized environment running most of the off-the-shelf components, thanks partly to our colleagues at EDINA who are doing the SOLR implementation. We are beginning to add LOCKSS-specific services to it, starting with the metadata extraction service and the metadata database.
No comments:
Post a Comment